
1. Modality
Each source or form of information.
•
Sound
•
Video
•
Text
•
Visual Cues
•
Sensor Data (radar, infrared, accelerometer)
1-1. Visual Guidance
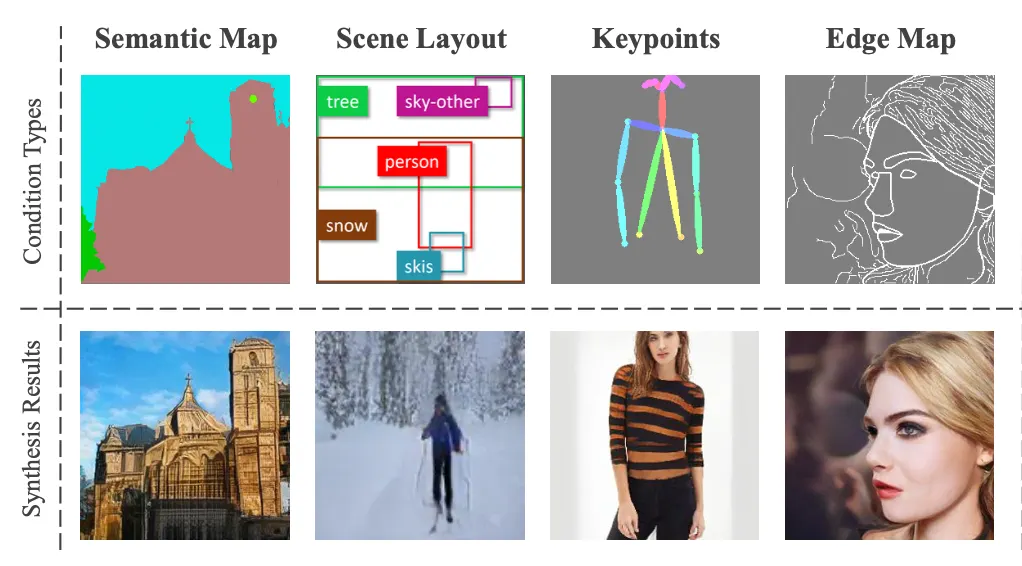
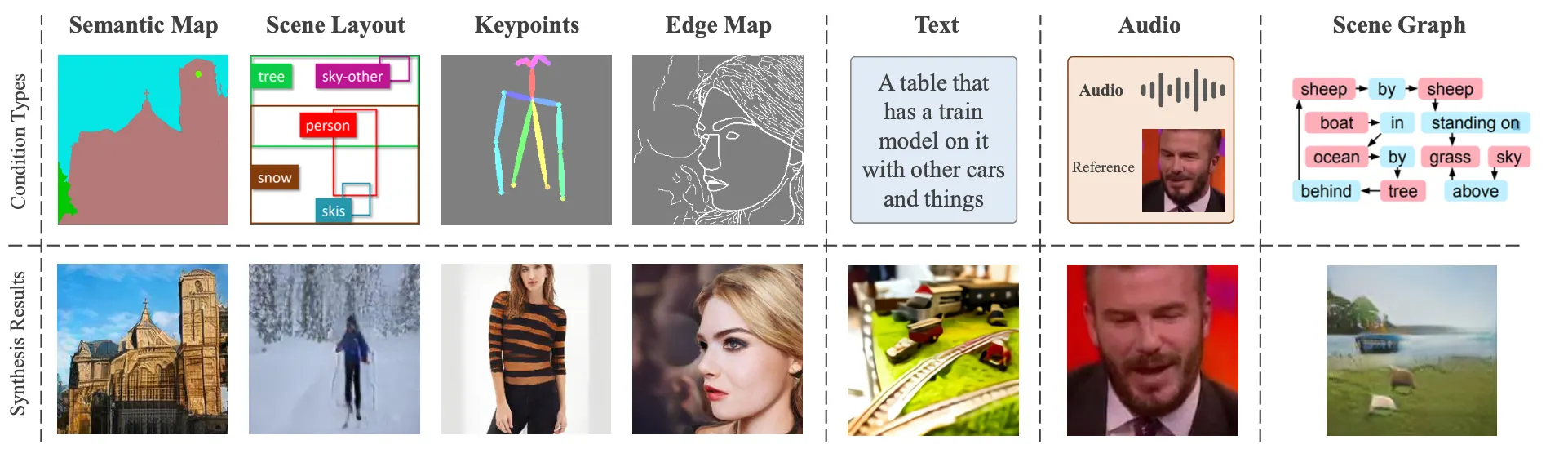
Visual Guidance 의 종류
•
Segmentation Map
•
Keypoints
•
Edge Map
•
Scene Layout
Visual Guidance의 특징
•
이미지와 Paired vs. Unpaired
•
Visual Guidance를 수정하면 이미지에 직접적으로 반영된다.
•
Applications Image Colorization, Super-resolution, de-haze, de-rain.
1-2. Text Guidance
•
입력된 텍스트에 대응되는 semantic relevance한 이미지를 생성한다.
•
Visual Guidance에 비해 더욱 유연하게 결과 이미지를 생성할 수 있다.
•
어려운 점 text가 모호하거나 여러 의미를 가지고 있다는 점이다.
Text Encoding
•
텍스트로부터 의미를 추출하여 text representation을 잘 만드는 작업은 매우 중요하다.
Word2Vec
Bag-of-Words
Reed et. al.
AttnGAN
StackGAN
BERT
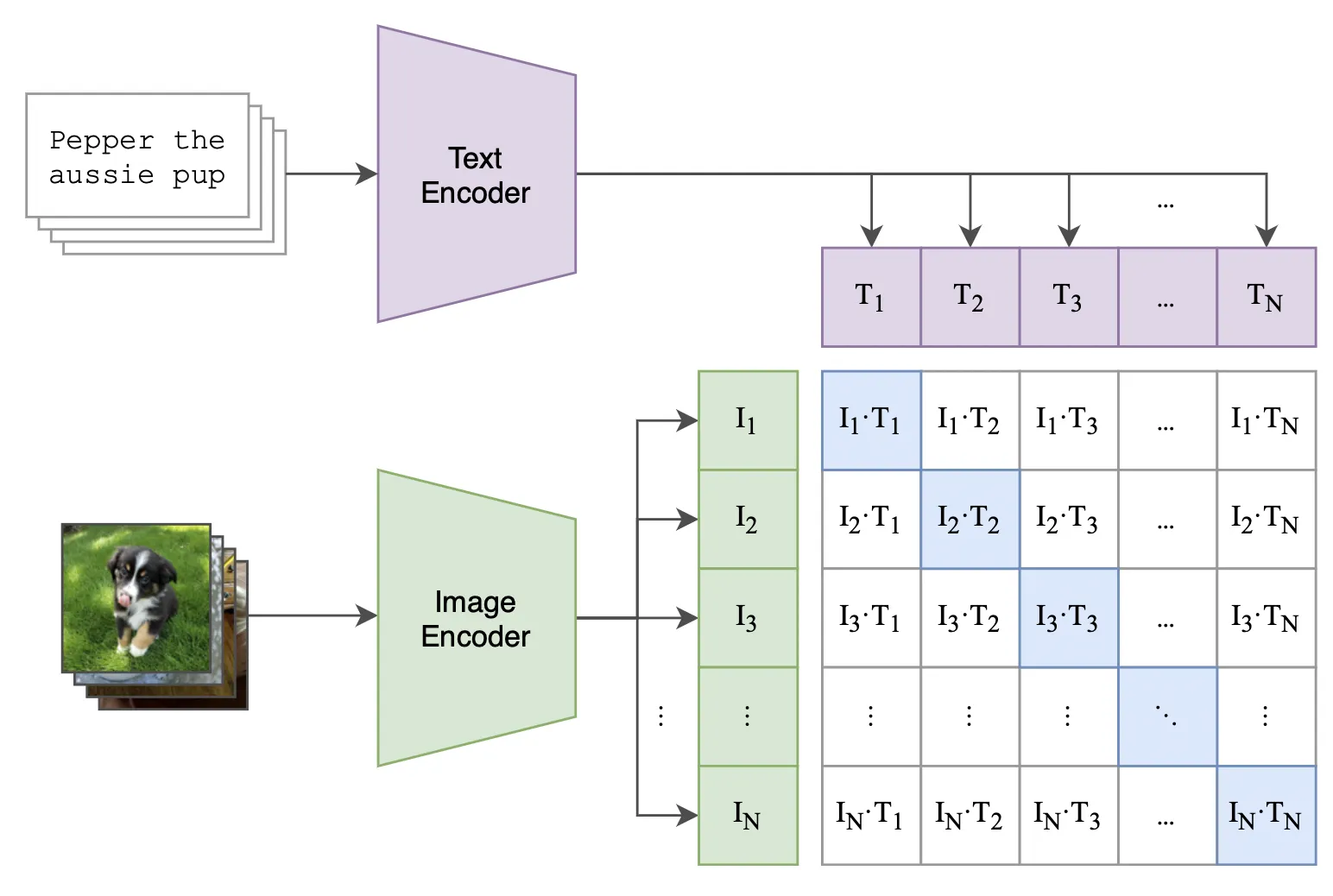
CLIP
2. Methods
Multimodal image synthesis는 크게 4가지 카테고리로 구분될 수 있다.
•
GAN Based methods
•
GAN inversion methods
•
Transformer-based methods
•
Other methods
2-1. GAN-Based Methods
2-1.1 Paired Visual Guidance
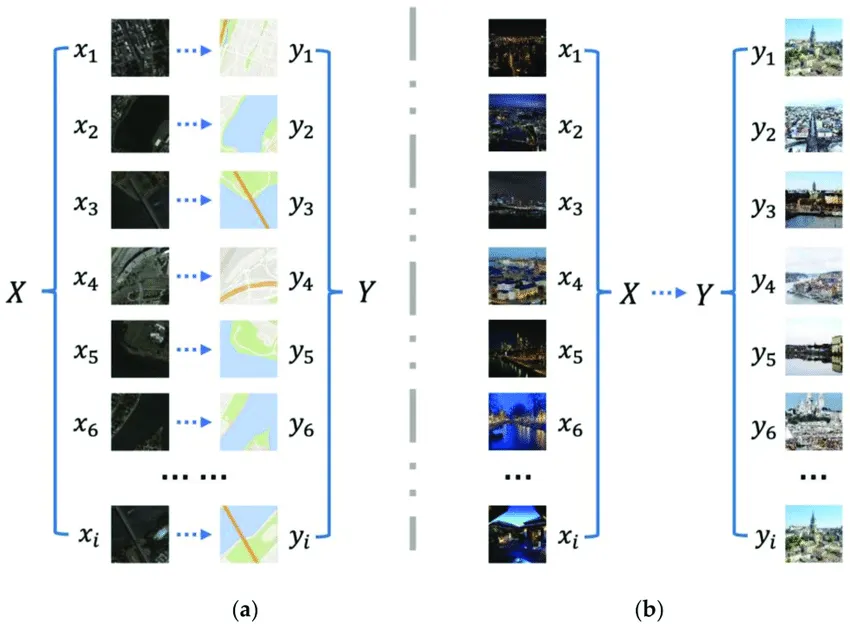
(a) Paired (b) Unpaired
•
이미지와 Ground Truth가 paired 된 Guidance로 제공되는 유형
•
Adversariual loss를 제외하고, 보통 generated image와의 supervised loss를 사용한다.
2-1.1.1 Semantic Image Synthesis
Pix2Pix (CVPR, 2017)
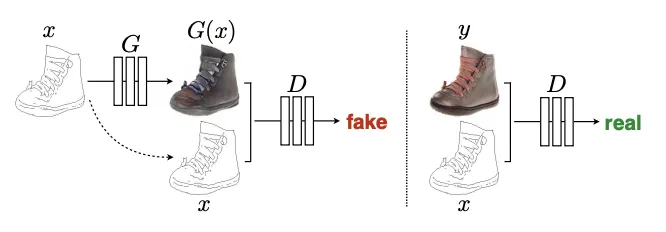
Training a conditional GAN to map edges→photo. The discriminator, D, learns to classify between fake (synthesized by the generator) and real {edge, photo} tuples. The generator, G, learns to fool the discriminator. Unlike an unconditional GAN, both the generator and discriminator observe the input edge map.
•
가장 간단한 구조의 초기 Conditional GAN 형태
Pix2pix HD (CVPR, 2018)
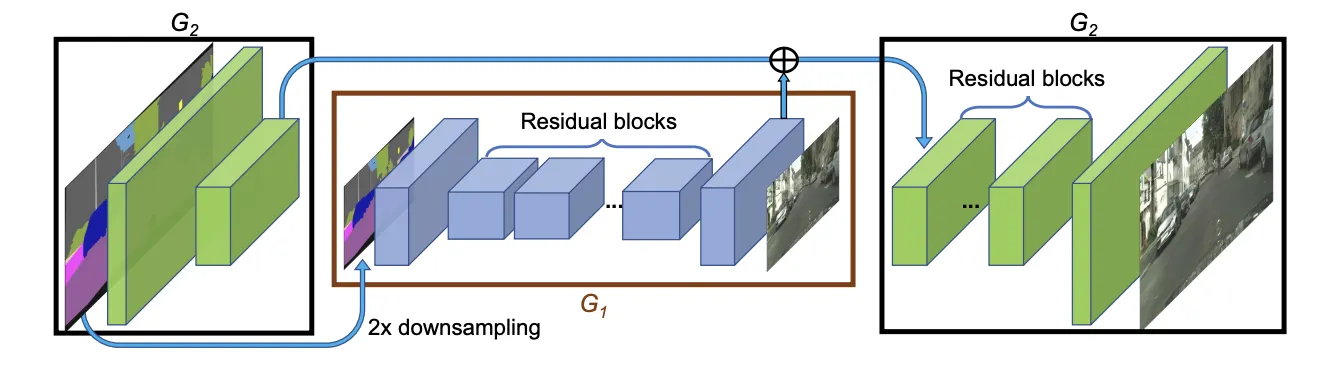
: Network architecture of our generator. We first train a residual network G1 on lower resolution images. Then, another residual network G2 is appended to G1 and the two networks are trained jointly on high resolution images. Specifically, the input to the residual blocks in G2 is the element-wise sum of the feature map from G2 and the last feature map from G1.
SelectionGAN (CVPR, 2019)
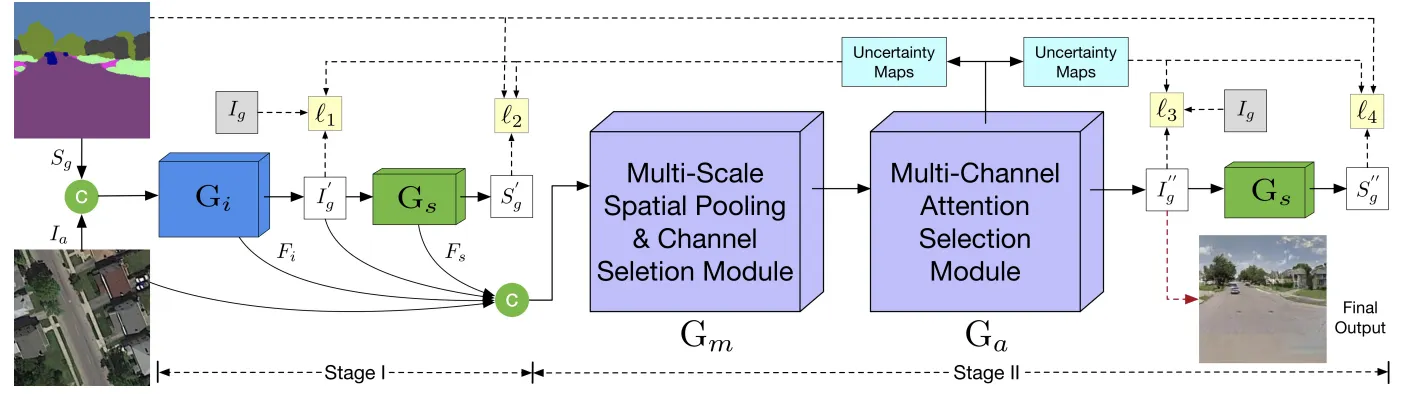
Overview of the proposed SelectionGAN. Stage I presents a cycled semantic-guided generation sub-network which accepts both the input image and the conditional semantic guidance, and simultaneously synthesizes the target images and reconstructs the semantic guidance. Stage II takes the coarse predictions and the learned deep features from stage I, and performs a fine-grained generation using the proposed multi-scale spatial pooling & channel selection and the multi-channel attention selection modules.
기존의 한계 Guidance에 한정되어 다양한 이미지 생성에 제약이 있었음 (특히 복잡한 형태나 디테일에서)
Attention Selection Module Cross-view guidance와 target-view를 정렬 (Align)하는 모듈을 제안
SPADE (CVPR, 2019)
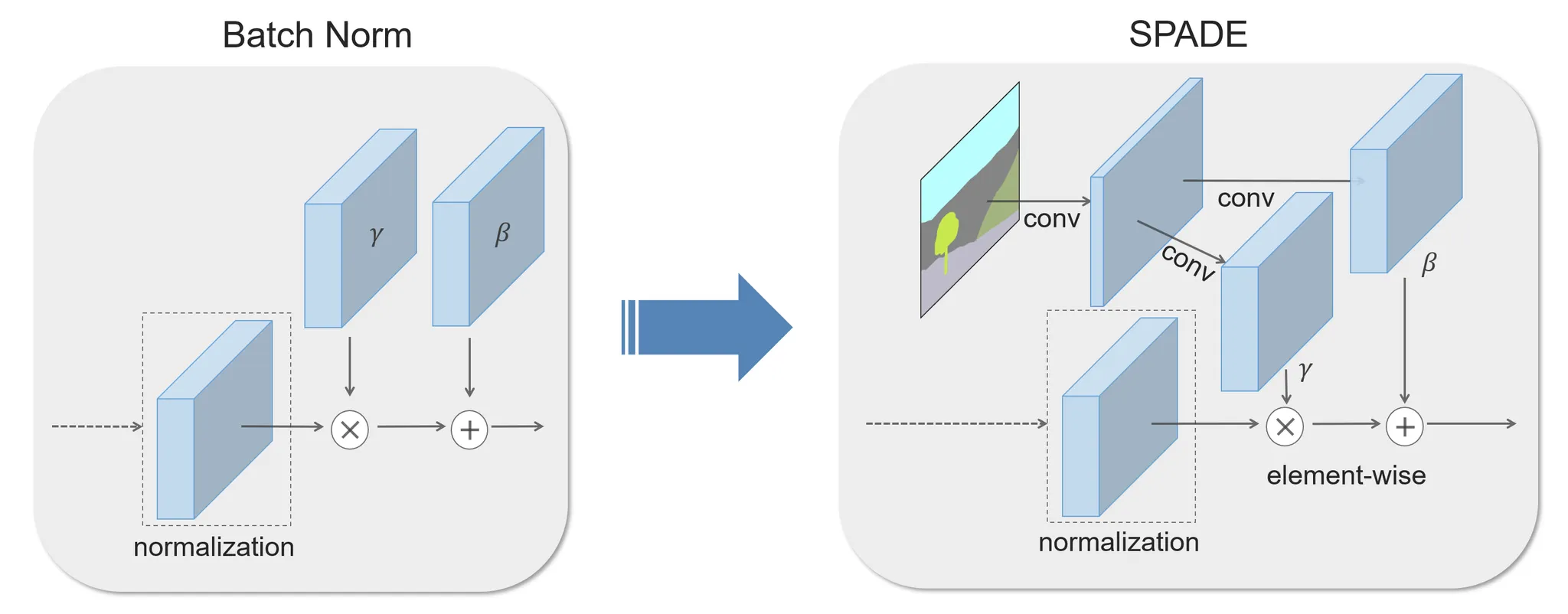
In the SPADE, the mask is first projected onto an embedding space and then convolved to produce the modulation parameters γ and β. Unlike prior conditional normalization methods, γ and β are not vectors, but tensors with spatial dimensions. The produced γ and β are multiplied and added to the normalized activation element-wise.
기존의 한계 Semantic Map을 직접적으로 encode해 norm 레이어에서 mean을 잃어버리는 문제가 있었음
SPADE Module Layer를 통해 spatially-adaptive한 gamma, beta를 추출
SEAN (CVPR, 2020)
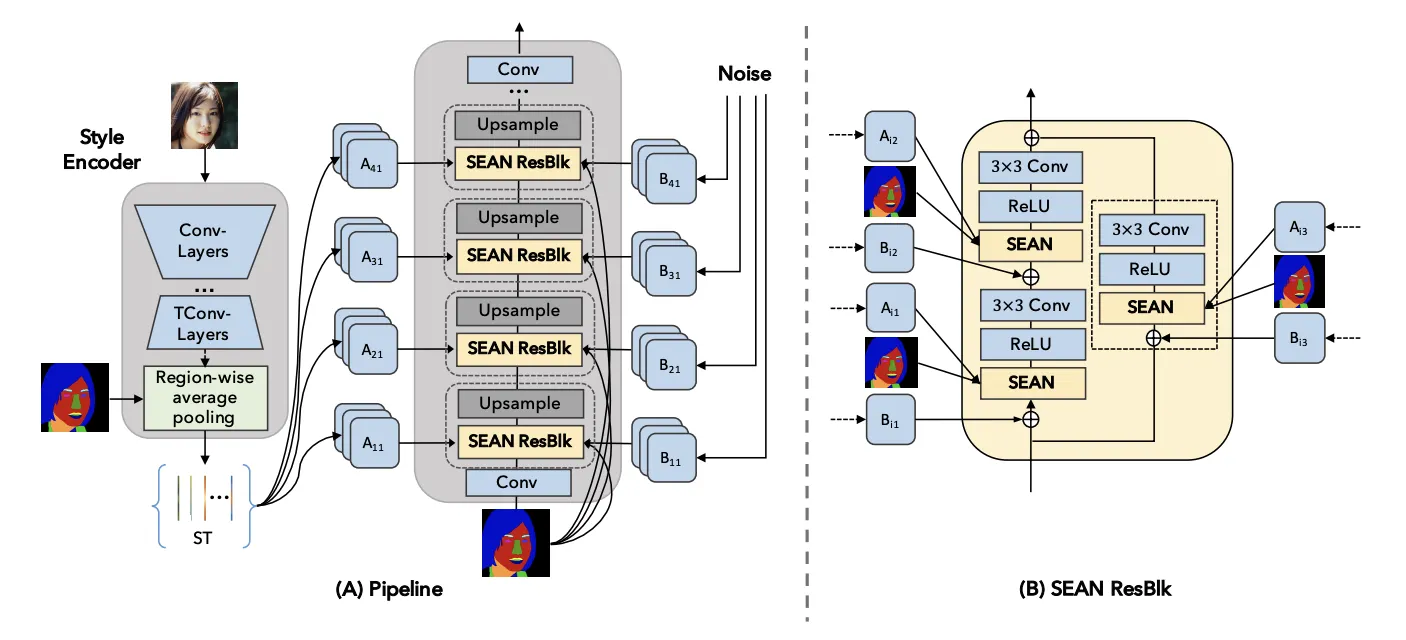
SEAN generator. (A) On the left, the style encoder takes an input image and outputs a style matrix ST. The generator on the right consists of interleaved SEAN ResBlocks and Upsampling layers. (B) A detailed view of a SEAN ResBlock used in (A).
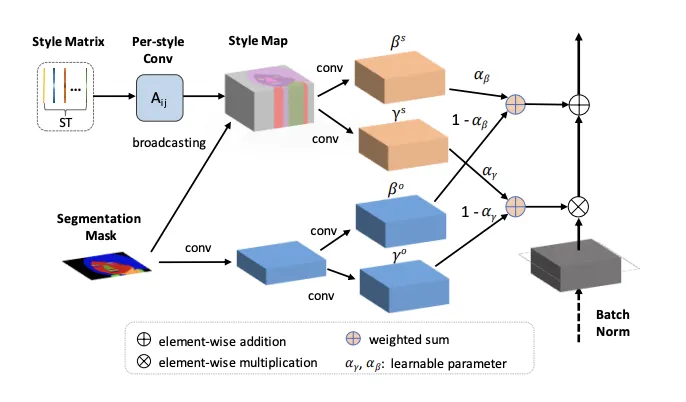
SEAN normalization. The input are style matrix ST and segmentation mask M. In the upper part, the style codes in ST undergo a per style convolution and are then broadcast to their corresponding regions according to M to yield a style map. The style map is processed by conv layers to produce per pixel normalization values γ s and β s . The lower part (light blue layers) creates per pixel normalization values using only the region information similar to SPADE.
CLADE (2020)
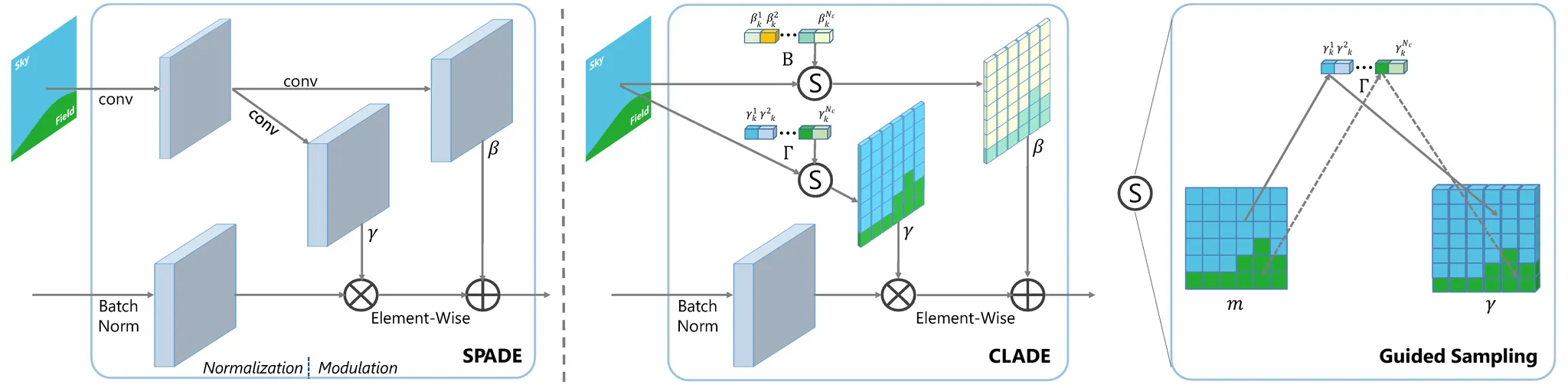
The illustration diagrams of SPADE (left) and our class-adaptive normalization layer CLADE with a guided sampling operation (right). Using a shallow modulation network consisting of two convolutional layers to model the modulation parameters γ, β as the function of input semantic mask, SPADE can add the semantic information lost in the normalization step back. Unlike SPADE, CLADE does not introduce any external modulation network but instead uses an efficient guided sampling operation to sample class-adaptive modulation parameters for each semantic region.
•
SPADE의 한계점
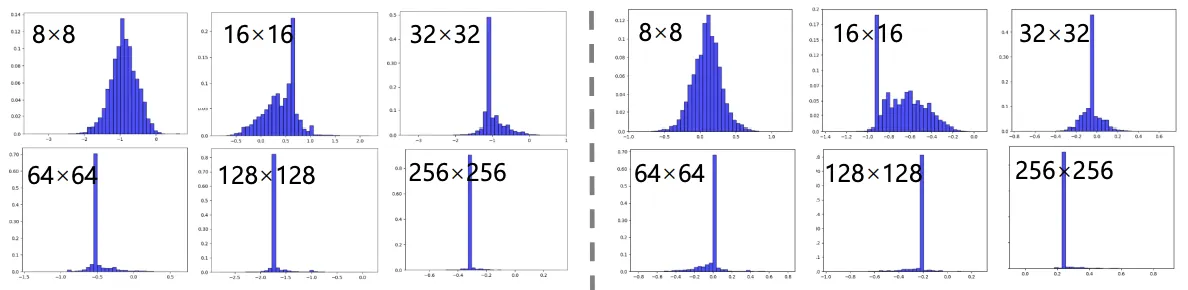
‘빌딩’ 카테고리에 대한 (좌) Gamma와 (우) Beta
•
저자는 먼저 spade에서 출력되는 와 의 히스토그램을 분석했다.
•
Resolution이 커질 수록 distribution은 concentrated, centralized 되는 경향이 뚜렷하게 보였다.
•
즉, spatially-adaptive 하다는 SPADE저자의 주장과는 다르게 한 값만을 취하면 충분했다.
class-adaptive normalization layer Class별로 gamma와 beta의 memory bank를 만들면 충분했다.
Position EncodingSpatially-adaptive를 유지하기 위해 여러가지 P.E.를 시도한다.
따라서 최종적으로 아래와 같은 모듈을 만든다.
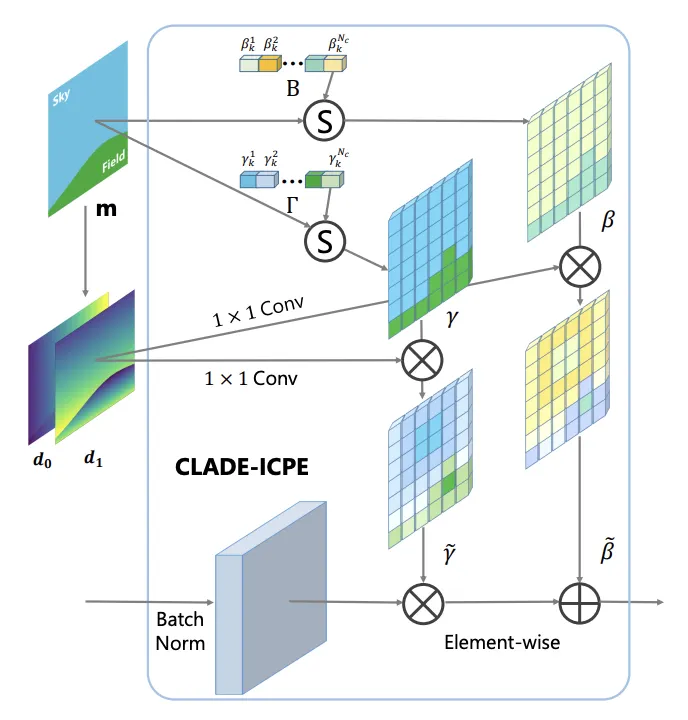
The illustration of class-adaptive normalization layer (CLADE) with intra-class positional encoding (ICPE). The positional encoding map is calculated from the semantic segmentation map. d0 and d1 represent the positional encoding along the x, y dimension.
INADE (2021)
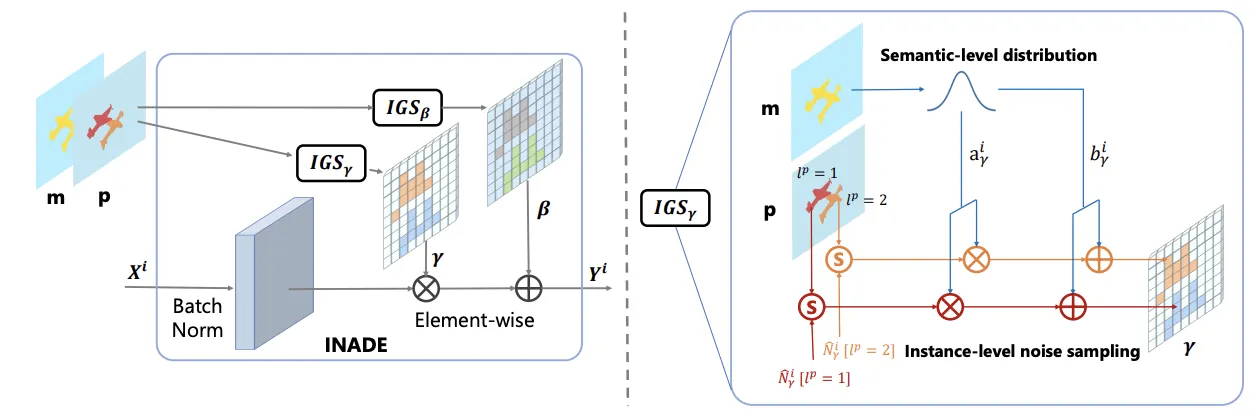
The illustration diagram of the proposed INstance-Adaptive DEnormalization (INADE). It combines semantic-level distribution modeling and instance-level noise sampling. IGS denotes the Instance Guided Sampling which is similar to the guided sampling in [37].
•
CLADE의 Instance-wise 버전.
•
한발 더 나아가, class semantic으로부터 의 와 의 를 구한다.
•
이로부터 각 클래스의 PDF를 만들고, 각 인스턴스의 를 sampling한다.
•
두번 꼬아서 복잡해보이지만, 굉장히 간단하고 직관적인 해결 방법.
ASAP-Net (2021)
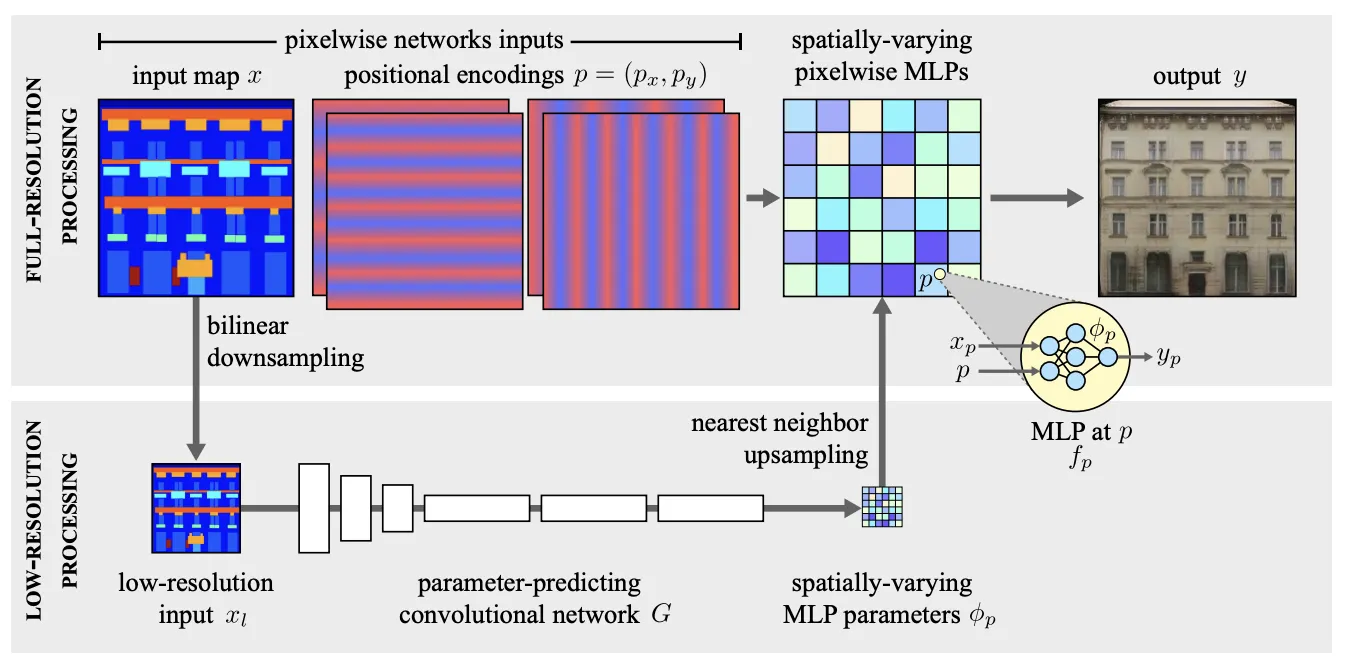
Our model first processes the input at very low-resolution, xl , to produce a tensor of weights and biases φp. These are upsampled back to full-resolution, where they parameterize pixelwise, spatially-varying MLPs fp that compute the final output y from the high-resolution input x. In practice, we found nearest neighbor upsampling to be sufficient, which means that the MLP parameters are in fact piecewise constant.
•
Hypernetwork 에서 영감받은 구조를 도입
•
매우 가볍고 빠른 network를 만들었다.
•
당시 유행하던 기억이 있다.
•
CoCosNet (2020)
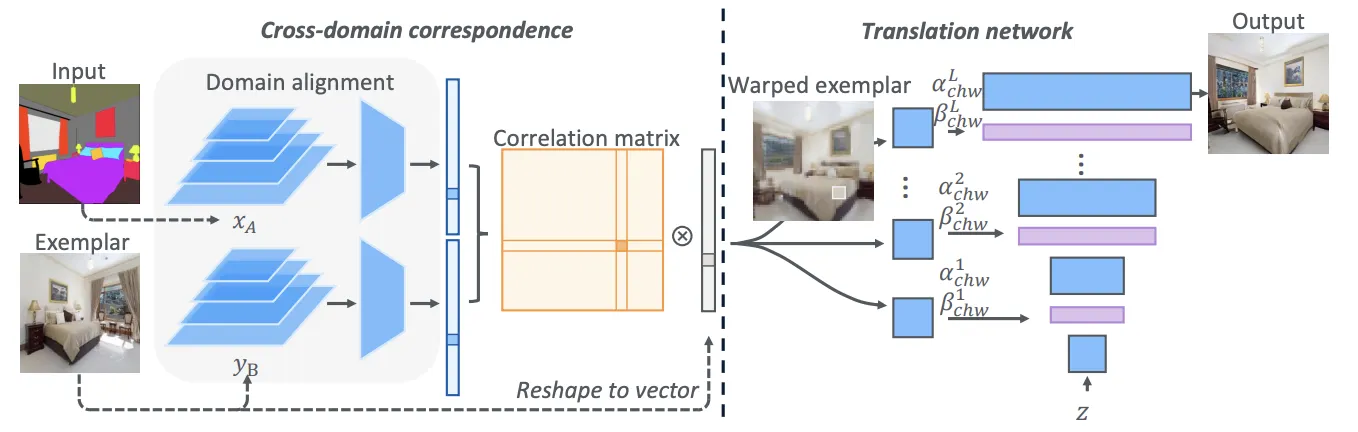
Given the input xA ∈ A and the exemplar yB ∈ B, the correspondence submodule adapts them into the same domain S, where dense correspondence can be established. Then, the translation network generates the final output based on the warped exemplar ry→x according to the correspondence, yielding an exemplar-based translation output.
•
Examplar-based Framework 스타일을 Examplar라고 부르기 시작한 듯.
•
Semantic과 Examplar 간의 correlation을 구하고 semantic에 correlate하는 warped examplar를 만든다.
•
Translation Network warped examplar로부터 StyleGAN 으로 이미지를 생성
•
논문의 한계 Dense Correspondence를 구성하는데 굉장히 많은 메모리가 소요된다.
•
CoCosNet v2 (CVPR, 2021)
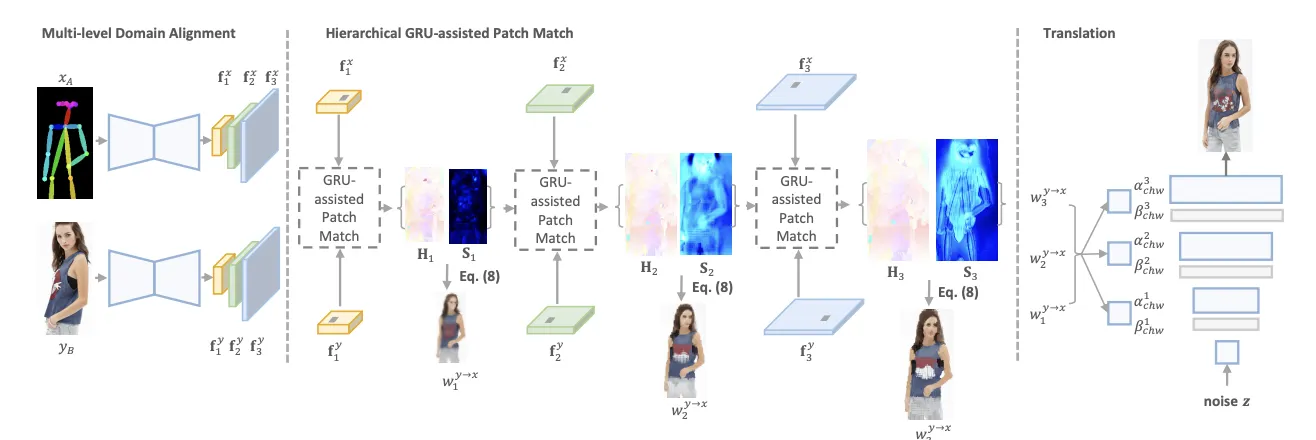
The overall architecture of CoCosNet v2. We learn the cross-domain correspondence in full resolution, by which we warp the exemplar images (w_i^{y→x}) and feed them into the translation network for further rendering. The full-resolution correspondence is learned hierarchically, where the low-resolution result serves as the initialization for the next level. In each level, the correspondence can be efficiently computed via differentiable PatchMatch, followed by ConvGRU for recurrent refinement.
•
위와 같이 Examplar와 Condition간의 correlation을 구하는 것이 핵심이다.
•
•
Dense Correspondence를 구성하는데 드는 많은 메모리를 해결한 것이 핵심.
RABIT (ECCV, 2022)
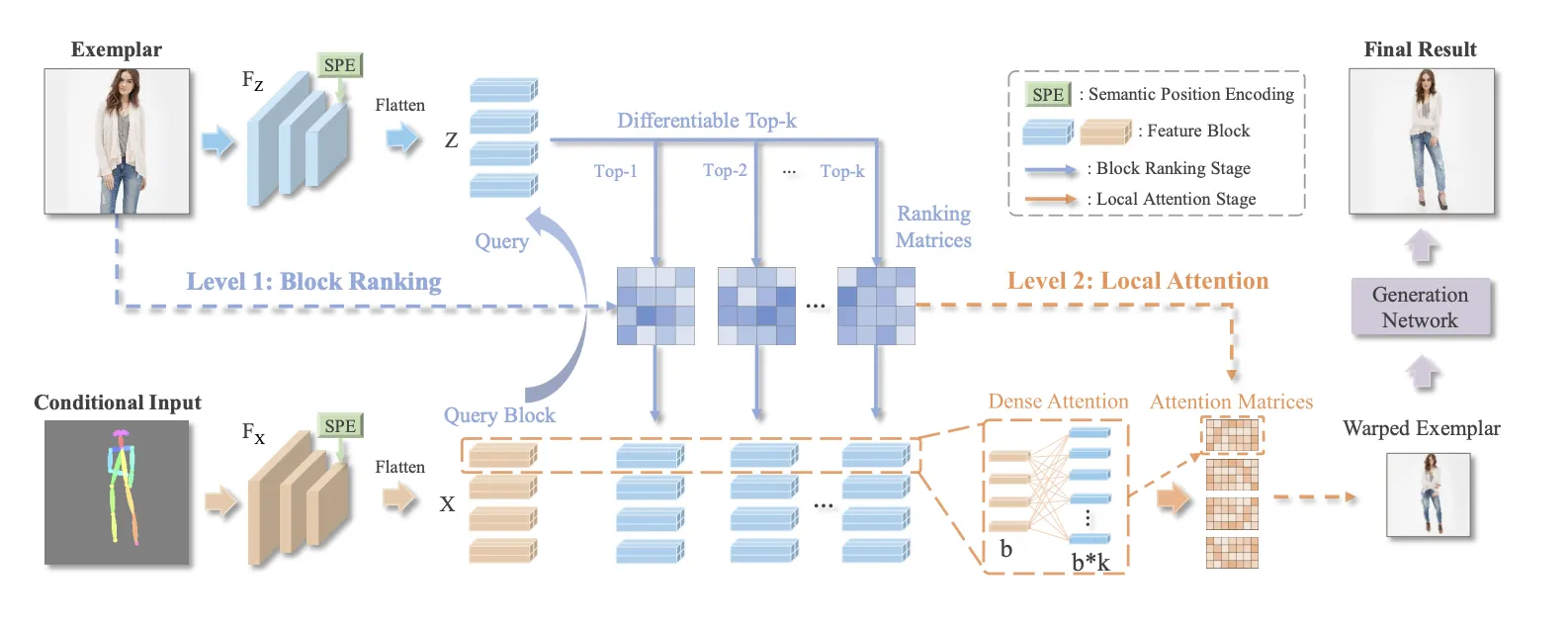
The framework of the proposed RABIT: Conditional Input and Exemplar are fed to feature extractors FX and FZ to extract feature vectors X and Z where b local features form a feature block. In the first level, each block from the conditional input serves as the query to retrieve top-k similar blocks from the exemplar through a differentiable ranking operation. In the second level, Dense Attention is then built between the b features in query block and b ∗ k features in the retrieved blocks. The built Ranking atrices and Attention Matrices are combined to warp the exemplar to be aligned with the conditional input as in Warped Exemplar, which serves as a style guidance to generate the final result through a generation network.
•
위와 같은 방법이다.
•
이때는 Top-K와 Dense Attention을 도입하였다.
2-1.1.2 Image Translation (Non-diterministic)
BicycleGAN (NIPS, 2017)
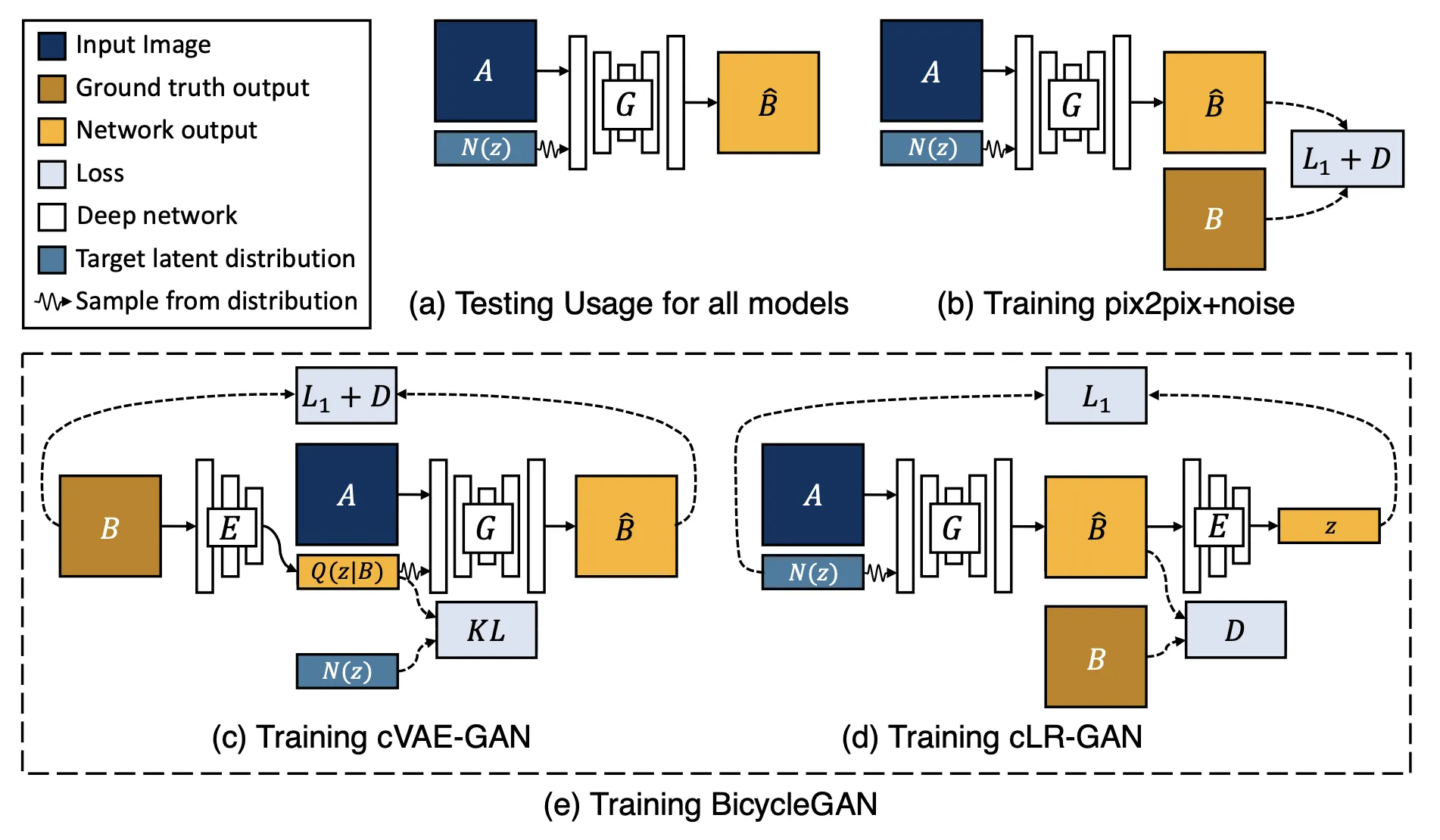
(a) Test time usage of all the methods. To produce a sample output, a latent code z is first randomly sampled from a known distribution (e.g., a standard normal distribution). A generator G maps an input image A (blue) and the latent sample z to produce a output sample Bˆ (yellow). (b) pix2pix+noise [20] baseline, with an additional ground truth image B (brown) that corresponds to A. (c) cVAE-GAN (and cAE-GAN) starts from a ground truth target image B and encode it into the latent space. The generator then attempts to map the input image A along with a sampled z back into the original image B. (d) cLR-GAN randomly samples a latent code from a known distribution, uses it to map A into the output Bˆ, and then tries to reconstruct the latent code from the output. (e) Our hybrid BicycleGAN method combines constraints in both directions.
•
cVAE-GAN + cLR-GAN
2-1.1.3 Disentangle Method
•
Disentangled Representation 이란,
Gaussian distribution으로부터 disentangled feature (스타일 등) 을 randomly sampling 해서 diverse한 output을 얻는 방법이다.
◦
•
Cross-domain disentantanglement network (2018, NeurIPS)
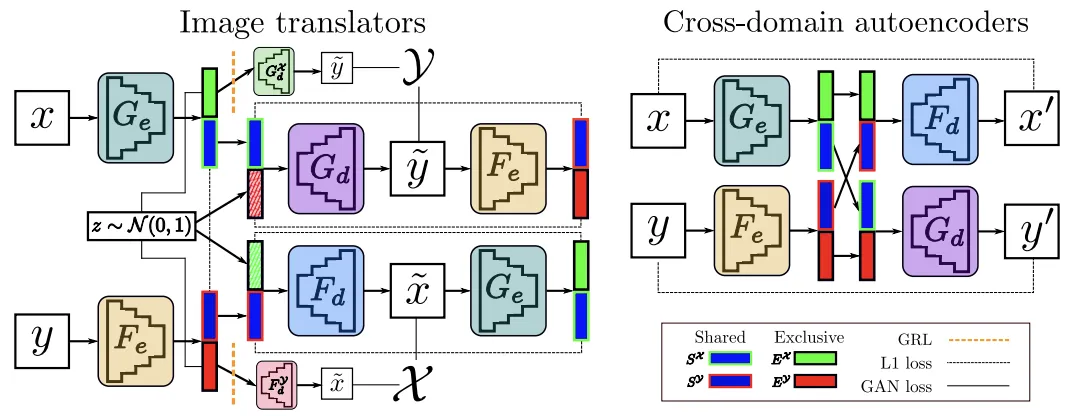
Overview of our model. (Left) Image translation blocks, G and F, based on an encoder-decoder architecture. We enforce representation disentanglement through the combination of several losses and a GRL. (Right) Cross-domain autoencoders help aligning the latent space and impose further disentanglement constraints.
•
Domain feature representation 을 disentangle 해서 도메인 사이의 shared parts를 찾아냄 (content)
•
그리고 각 도메인에 exclusive 한 parts를 diverse generation을 가능케 한다는 것을 확인 (style)
•
Style과 content를 분리한다는게 무슨 말인지 감이 잘 안왔는데, 이 부분을 뜻하는 것 같다.
2-1.2 Unaired Visual Guidance
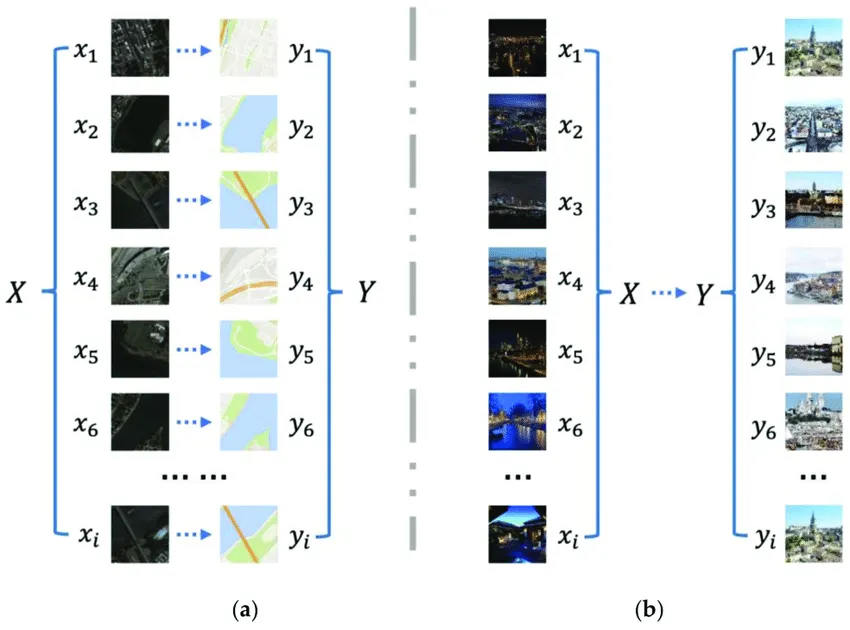
(a) Paired (b) Unpaired
•
한 도메인에서 다른 도메인으로의 변환을 학습한다.