
Zero-shot Image-to-Image Translation

Intro & Overview
•
Image-to-Image Translation을 Train-free로 하기 위한 방법을 제안한다.
•
장점: Training-free, Prompt-free
•
단점:
Methodology
•
Zero-shot image to image translation 과정은 다음과 같이 이루어진다.
1.
Inversion: Source image를 노이즈로 Inversion한다. (Autocorrelation regularization)
2.
Finding direction: FROM : TO (cat : dog)의 클립 임베딩 추출로 변환 벡터 찾기
3.
Preserve Content: Cross-attention을 통해 content 유지하기(이미지 변형을 최소화)
•
Conditional GAN distillation: Diffusion 대신 GAN 방식으로 보다 이미지를 빠르게 생성하는 방식으로 Diffusion 모델을 distill한다.
1. Deterministic Inversion.
Inversion은 를 복구 (reconstruct) 할 수 있는 노이즈맵 를 찾는 Task이다. 이는 간단히 Reverse Process의 역과정으로 이루어진다. 이때 DDPM의 경우 stochastic한 특성이 있기 때문에 deterministic한 DDIM을 사용한다. DDIM reverse process는 다음과 같다:
이를 Deterministic하게 바꾸어주면 아래와 같이 정리된다.
이렇게 invert된 Noise map은 statistical property를 따르지 않는 문제가 있다. (uncorrelated, Gaussian white noise) 가우시안 노이즈는 random location의 어떤 pair에서도 correlation이 없어야 한다. 그리고 모든 포인트에 대해 zero-mean, unit-variance를 가져야 한다. 따라서 가우시안 노이즈의 autocorrelation function 은 Kronecker delta function이 된다.
따라서 저자는 inversion process를 가이드하기 위해 auto-correlation objective를 설정한다.
•
: pairwise regularization term
뜯어보자. 각 피라미드 레벨 의 Normalize noise map 에 대해 auto-correlation 계수들의 sum of square가 된다. 이때 는 offset이고 은 spatial location의 index이다. 이 테크닉은 StyleGAN2에 사용되었다. 저자는 이 아이디어에 몇가지 수정을 가했다.
•
sample offset 를 1이 아닌 랜덤한 값으로 주어 long-range information의 전파 효과를 높임
•
: KL-Divergence at individual pixel location.
StyleGAN2에서는 zero-mean unitvariance criteria strictly via normalization를 사용했지만, 이는 diffusion에서 발산하는 결과를 가져왔다. 따라서 VAE에서 사용된 것처럼 KLD를 사용했다.
이렇게 Noise를 Regularize한 inversion noise map을 얻게 되었다.
2. Finding Editing direction.
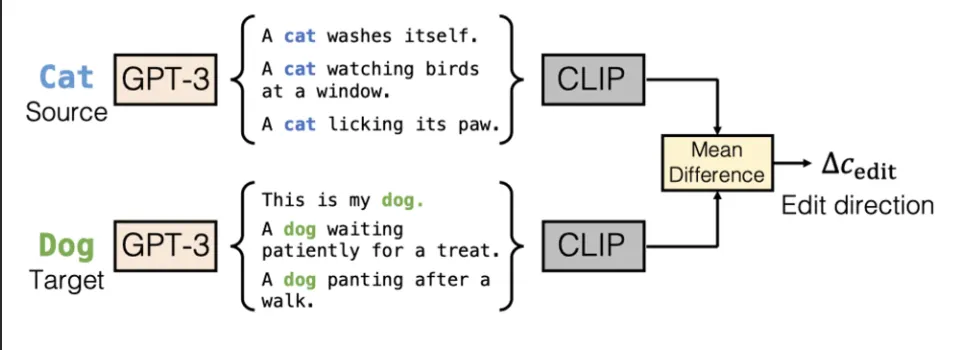
Edit의 방향을 찾는 것은 prompt와 CLIP 을 사용해 이루어진다.
1.
Prompt 생성 GPT-3를 이용해 captioning하거나 (Contextual Text Embedding) 템플릿을 이용한다.
a.
이때, Contextual Text Embedding모델에서는 각 단어의 임베딩이 다른 값이 되기 때문에 여러 문장을 mean한다.
2.
CLIP Distance 두 prompt간의 CLIP Embedding feature에 대해 을 구한다. (mean difference)
3.
Sampling 을 condition으로 주입해 이미지를 샘플링한다.
3. Edit using Cross-Attention Guidance
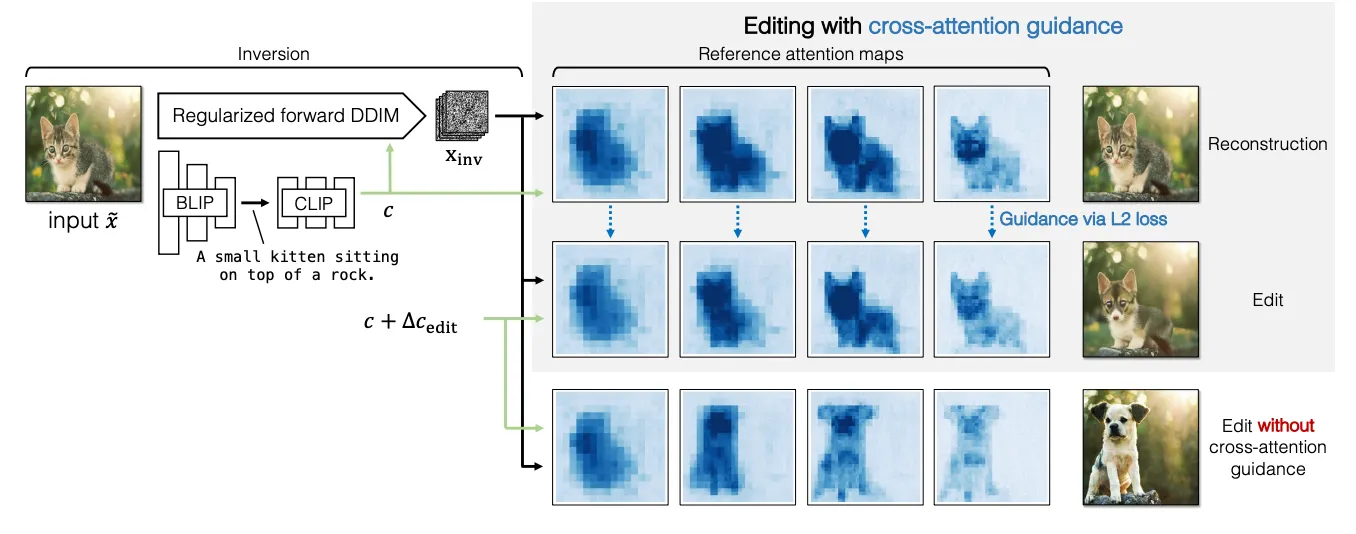
먼저, Naive하게 으로 샘플링해 보니 너무 과하게 이미지가 수정되는 것을 볼 수 있다. (그림 우하단). 샘플은 원본 이미지의 domain-independent feature인 structure와 배경, 컬러등은 일정하게 유지해야 한다. 이를 해결하기 위해 cross-attention guidance를 디자인했다. 이는 2단계로 이루어진다.

1.
Rererence image (512X512) 를 DDIM Inversion해서 노이즈 를 구한다.
2.
이를 원본 prompt 에 대해 sampling한다. (reconstruction).
3.
: prompt 와 샘플 간 cross-attention map 를 얻게된다. (각 timestep별로)
이 map은 structure와 관계 있으므로 preserve해야 하는 target이 된다.
4.
: 이제 edit direction 를 사용해 cross-attention map 를 얻는다.
5.
: 두 map이 같아야 하므로 cross-attention loss 를 적용한다.
위 loss는 structure를 유지하는데 도움이 된다고 저자는 말한다.
매우 간단한 논문이다.
이 외에도 GAN을 사용해 속도를 높이는 방법 또한 제시하지만, 생략하겠다.

