Synthesizer: Rethinking Self-Attention for Transformer Models
Abstract
•
High-level에서 self-attention을 대체하는 방법을 고안
•
Dot Product → Learned Attention
Conclusion: Somtimes work, (a bit).
Background: Related Works
Transformer with Dot-product
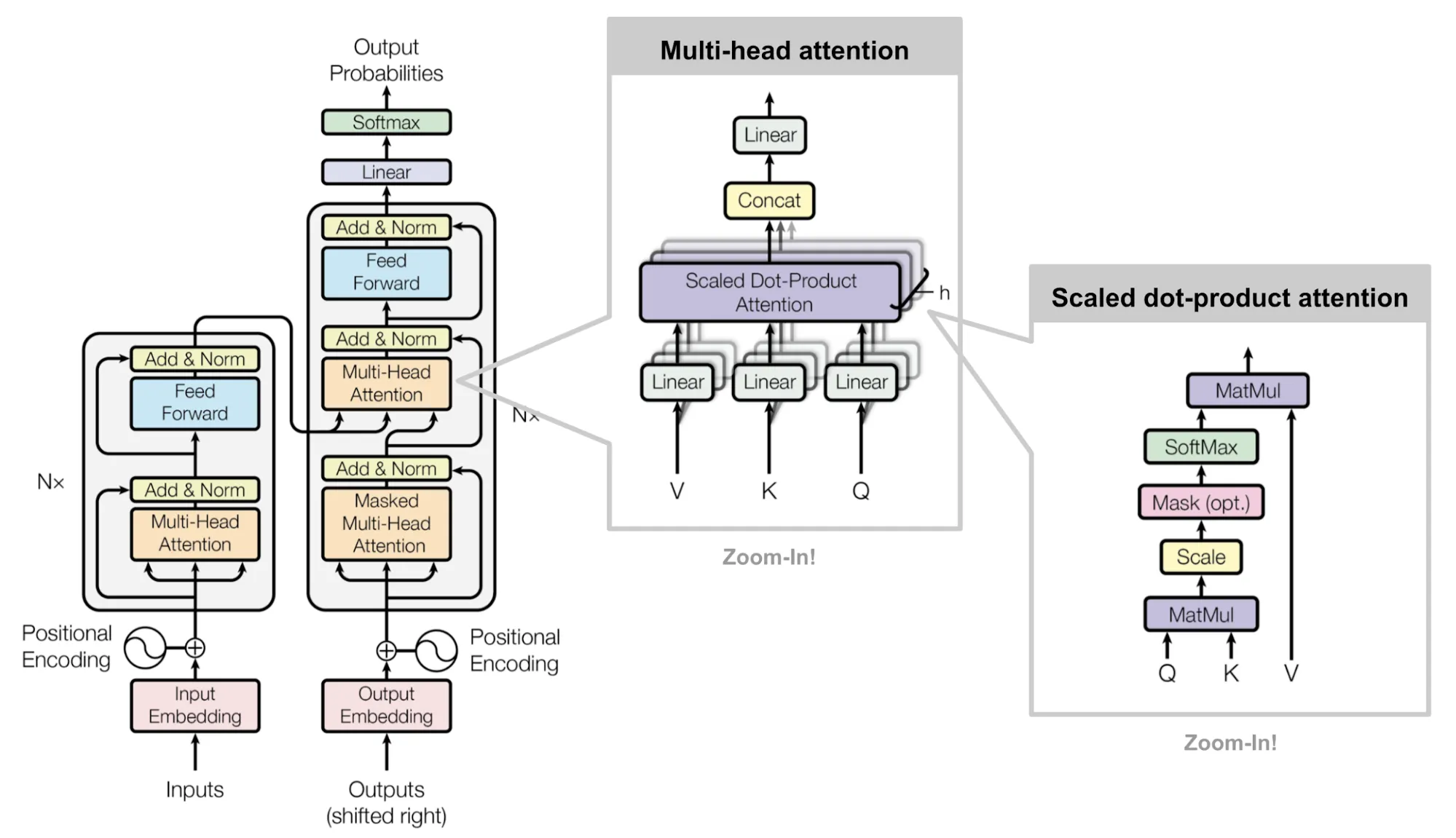
scaled dot-product는 매우 간단한 선형대수로 정의됩니다.
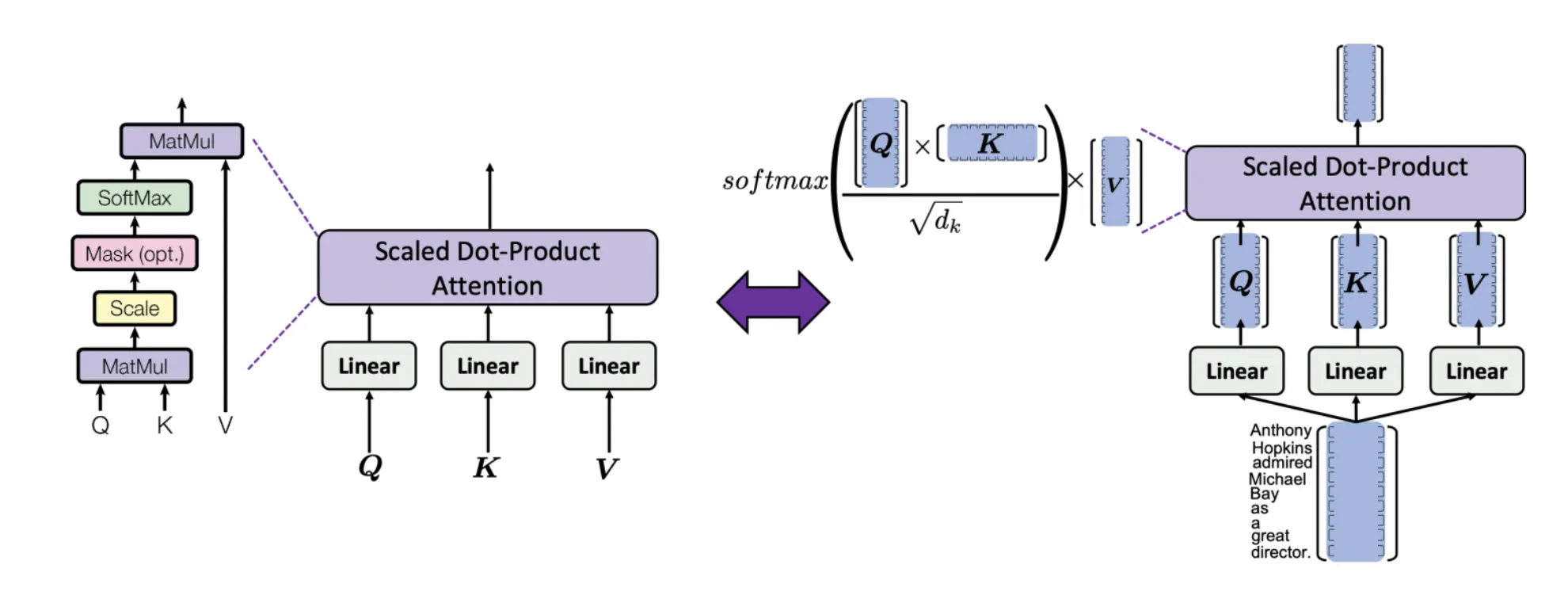
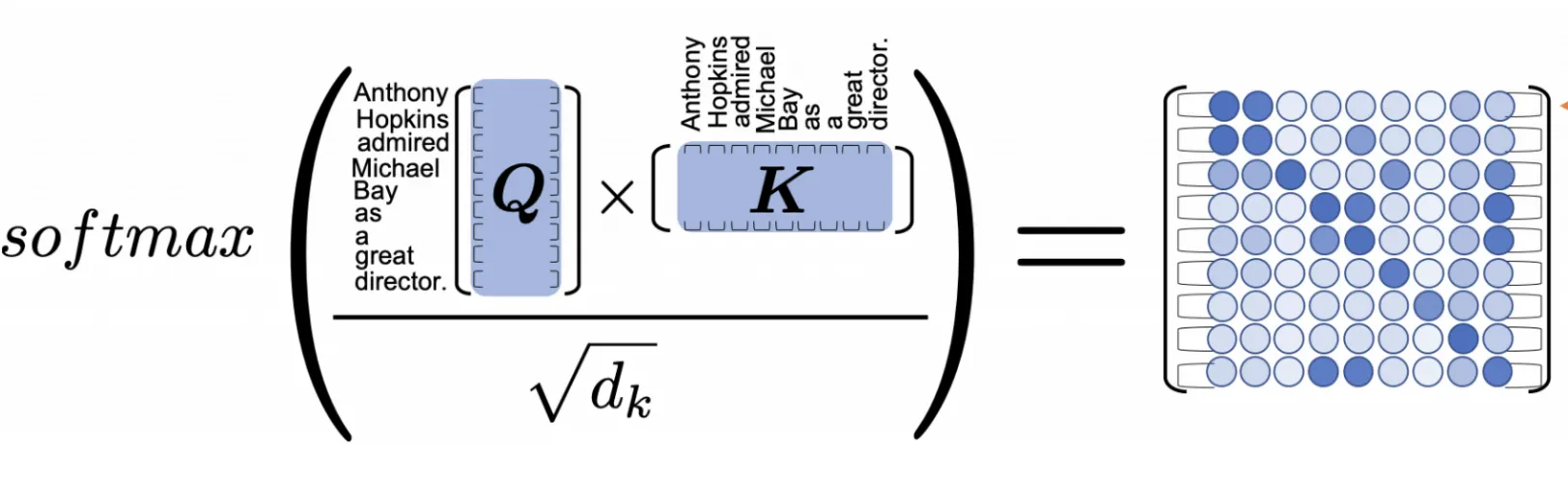
가 같은 길이의 문장이고 64dim이라고 하면, Attention matrix 크기는 다음과 같습니다.
즉 feature의 사이즈에 상관없이 각 토큰 사이 관계에 대한 attention을 얻게 됩니다.
Attention = Token-Token Interaction.
그렇다면 논문의 저자는 이에 대하여 질문합니다.

정말로 이러한 token-token interaction이 중요할까?
답을 미리 얘기하자면, "꼭 그렇지는 않은 듯" 이라는 결론을 내립니다.
Intro & Overview

•
Dot-product attention은, 각 query와 key 사이의 interaction (즉 token과 token 사이의 interaction)에 집중하고 있습니다.
◦
Individual Tokens
◦
token-token Interactions
◦
Global task Information
•
Synthesizer의 핵심은 다음과 같습니다.
"기존의 dot-product attention을 대체하면서 이러한 정보들을 잘 모델링 할 수 있다."
•
논문에서 제시된 Synthesizer에는 두가지가 있습니다.
◦
Dense Synthesizer (individual token information)
◦
Random Synthesizer (global task information)
Methodology
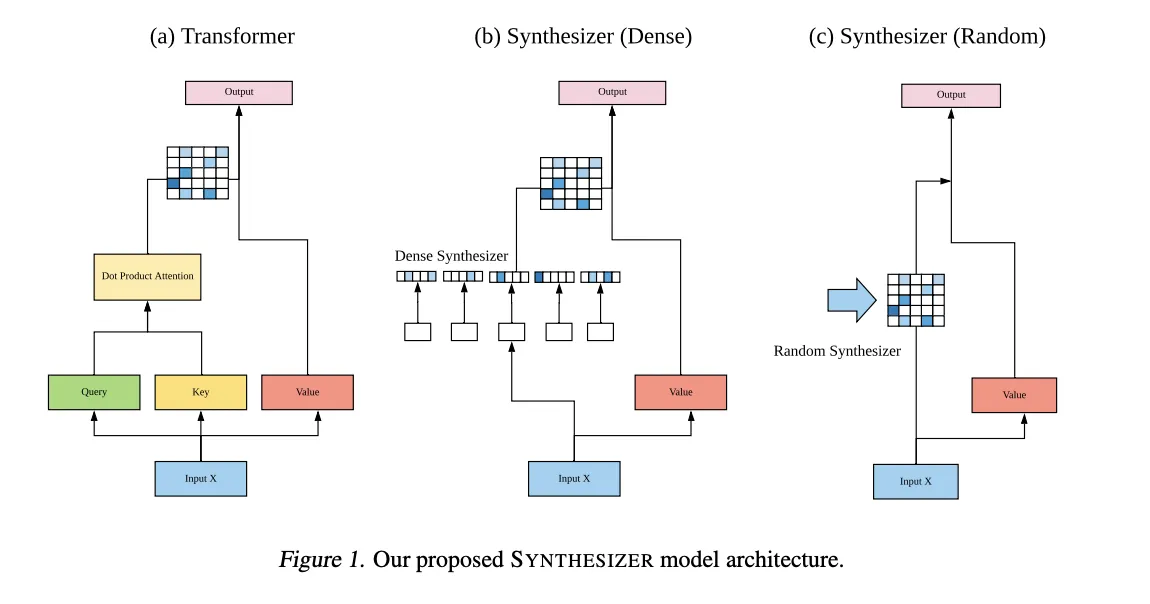
•
Transformer: 각 QK를 dot-product해서 attention matrix를 구한다.
•
Dense: Input X를 바탕으로 Q,K를 만들지 않고 각 토큰별로 값을 구해주어 concat.
•
Random: 랜덤 초기화 후 학습에 의해 조정한다.
Dot-product Attention
Dense Synthesizer
•
: Input.
•
•
, : Weights.
Random Synthesizer
•
: Random Initialize and Train.
Factorized Dense Synthesizer
•
•
◦
각 Token 별 Parameter 함수 로 구한 matrix.
•
: tiling functions: 벡터를 단순히 k번 반복하는 것.
◦
◦
◦
dims.
Factorized Random Synthesizer
•
•
Factorize의 장점: Sequence length가 길어질 때 parameter 증가를 상쇄시킬 수 있음.
Mixture Synthesizers
•
위 4개 모델을 복합적으로 사용함.
•
각 가 위 4개 중 어떤 것이라도 될 수 있다.
•
: per-head, multi-head의 헤드별로.
•
: per-layer, multi-layer의 레이어별로.
•
: Sequence Length
•
: model dimensionality
Experiments
Overview

•
Dot Product는 입력의 영향을 받아 Local한 특징을 가진다.
•
Random은 Attention Weight의 측면에서 입력의 영향을 받지 않아 Global하다.
•
Dense는 Token별로 쪼개긴 했지만 입력에 따라 영향을 받기 때문에 Local하다.
Experiment Results
1) Machine Translation
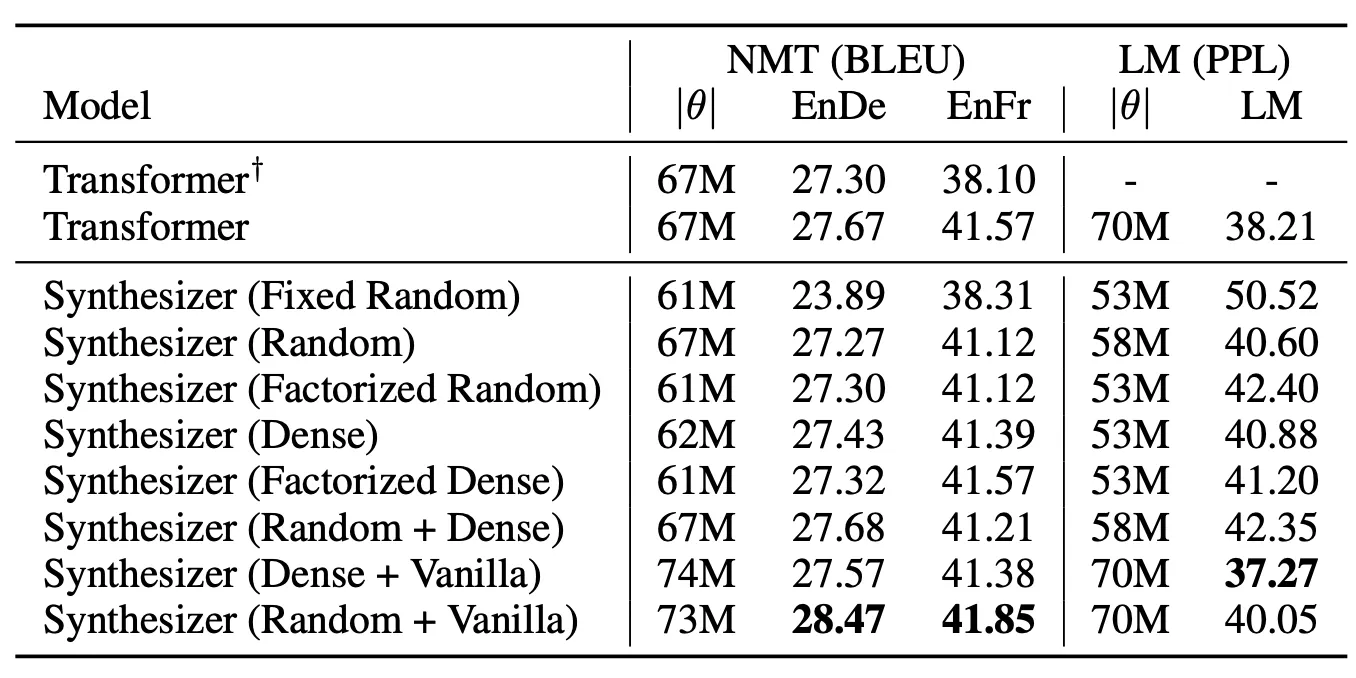
Table 2. 기계번역 실험결과. † 는 Transformer 원논문의 수치이다.
•
주목할 점은, Factorized Random이 은근 성능이 좋다는 점이다.
2) Text Generation
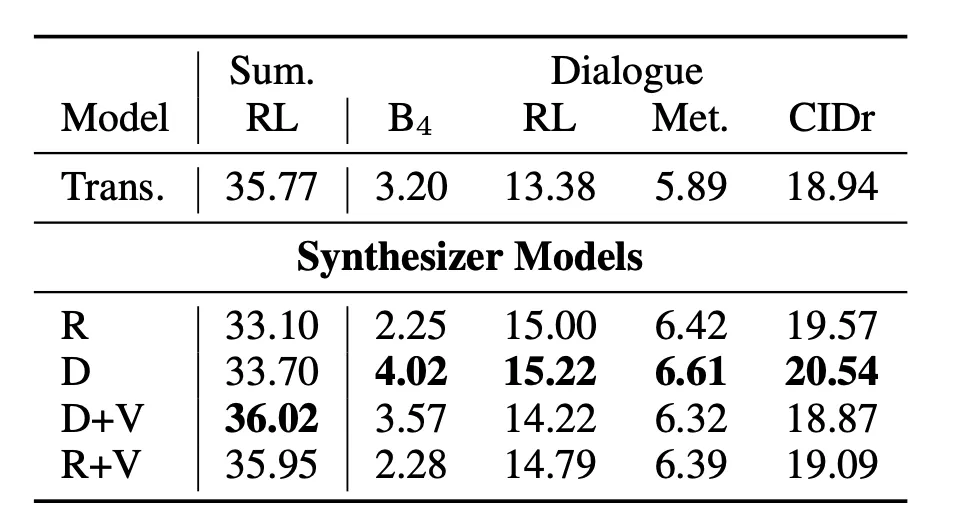
Table 1. Text 생성 실험 결과. 뉴스 요약 (CNN/Dailymail) 과 대화 생성 (PersonaChat).
•
텍스트 요약 모델에서는 Dense + 바닐라 모델이 좋은 성능을 보여주었다.
•
대화 생성 모델에서는 Dense 모델이 좋은 성능을 보여주었다.
3) Masked Language Modeling
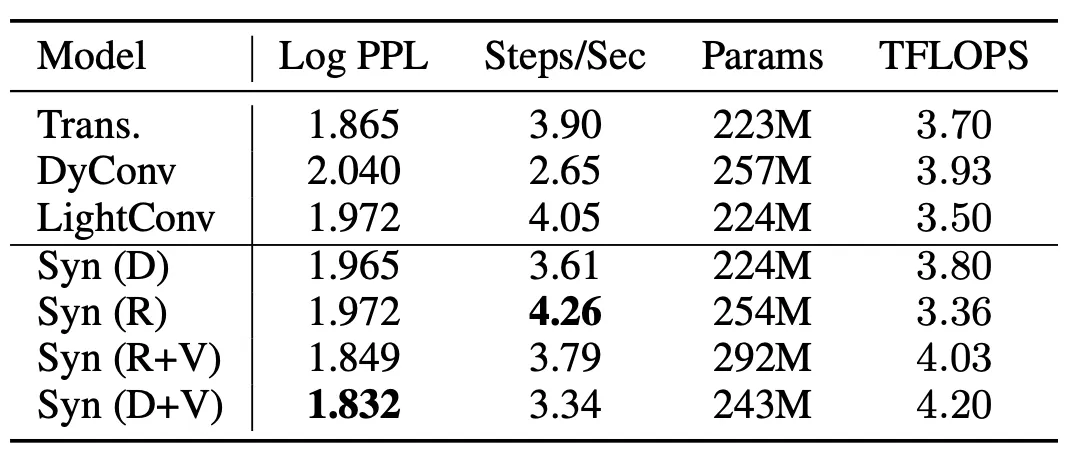
Table 4. Validation perplexity scores on C4 dataset (Raffel et al., 2019). 모든 모델이 거의 유사한 파라미터 설정.
4) GLUE Score
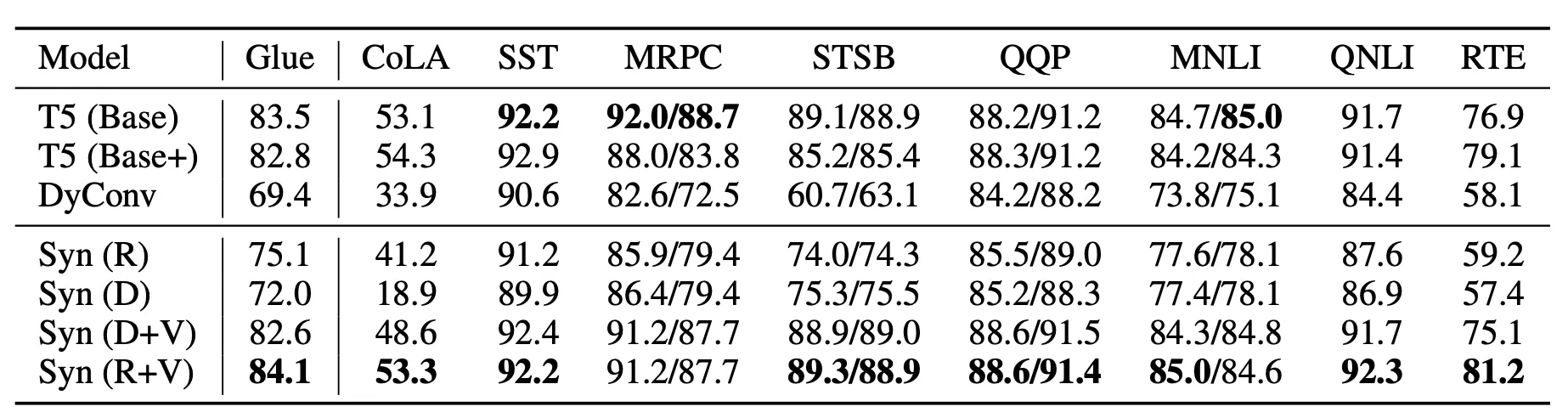
Experimental results (dev scores) on multi-task language understanding (GLUE benchmark) for small model and en-mix mixture. Note: This task has been co-trained with SuperGLUE.
•
이 경우 Random+Vanila가 좋은 성능을 보였다.
•
그 이유는 Global Understanding에 관한 Task이기 때문이다.
5) SuperGlue
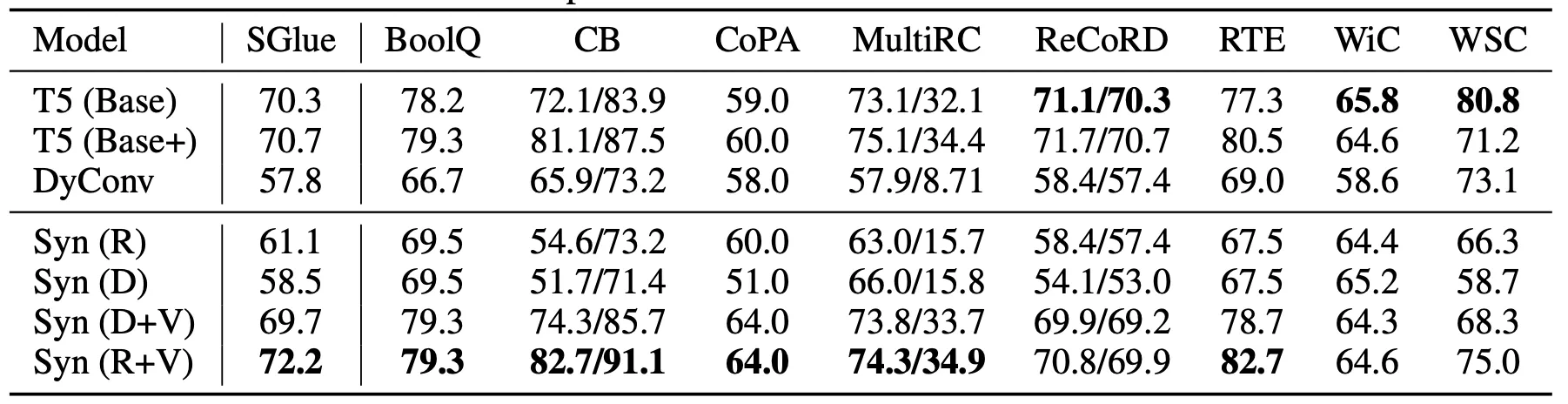
Experimental results (dev scores) on multi-task language understanding (SuperGLUE benchmark) for small model and en-mix mixture. Note: This task has been co-trained with GLUE.
•
종합적인 성능은 Synthesizer가 잘 나온다.
6) Comparison with Linformers
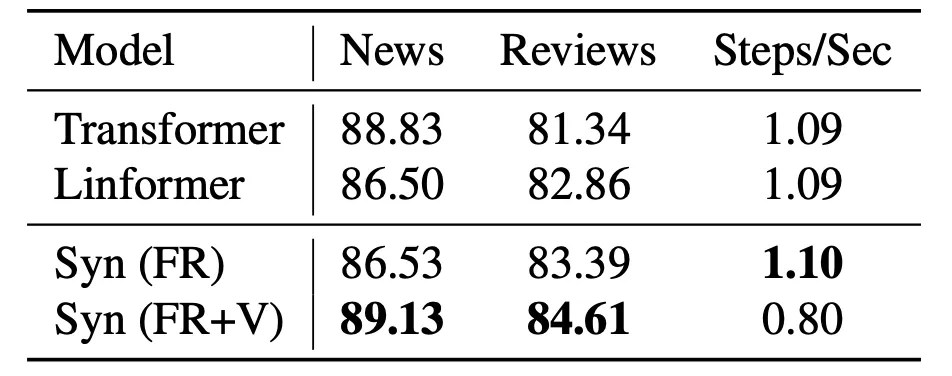
Results on Encoding only tasks
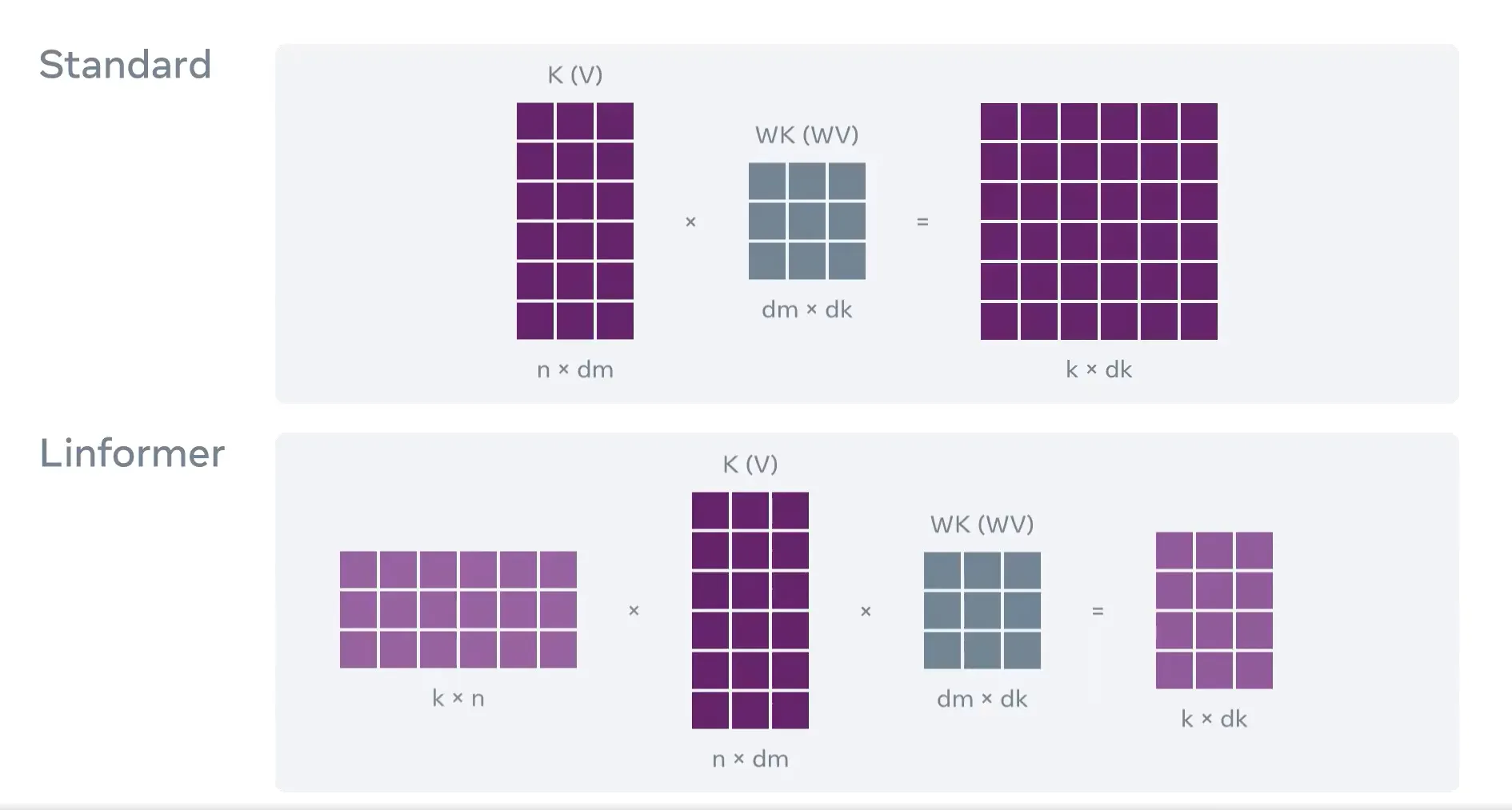
Linformer.
7) Qualitative Analysis
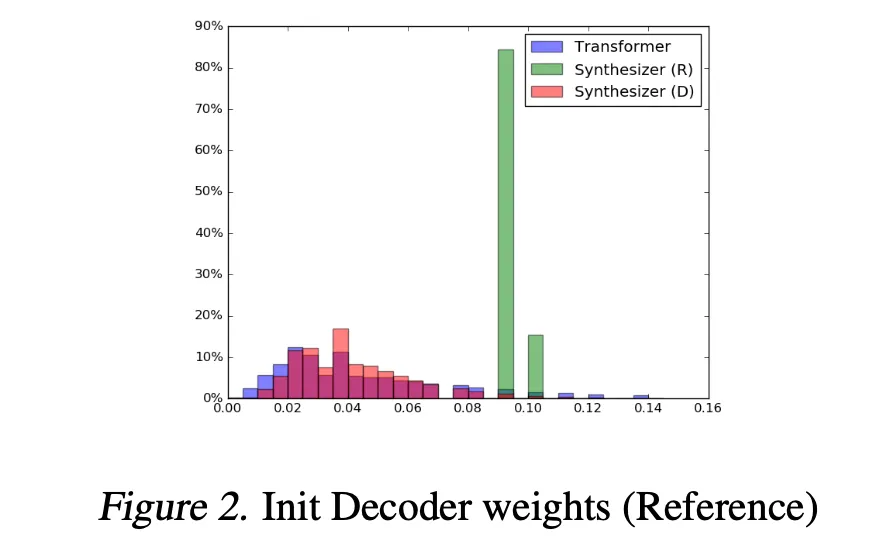
•
Initial State를 비교해보았다.
•
Random은 0.8~0.1사이에 mapping이 되어있다.
•
Transformer가 Synthesizer보다 더 넓은 Variance를 가지고 있다.
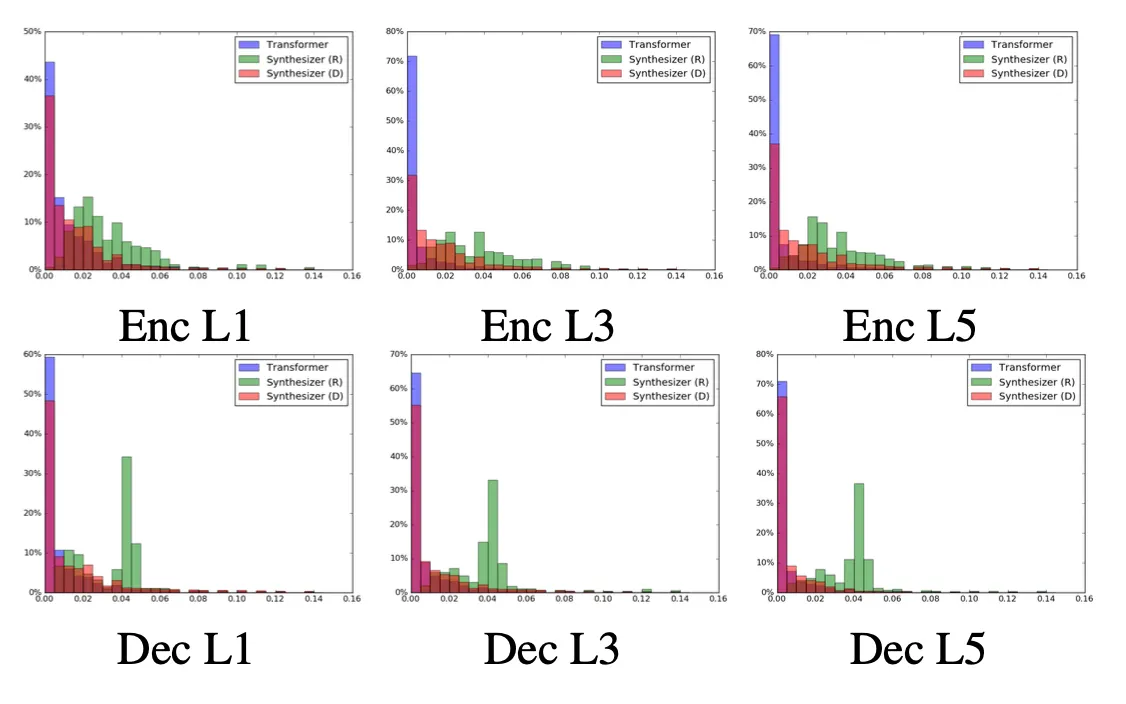
•
Transformer에 비해 0에 몰려있지 않고 더욱 고르게 분포가 되어있다.

•
Transformer에 비해 Synthesizer의 Attention Weight가 diffuse되어 보인다.
•
Dense모델은 Vanila모델과 유사한 분포를 가진다.
Conclusion
•
Synthesizer과 Dot-product는 상호보완적인 관계가 될 수 있다.
•
이를 이미지에 활용하면, 효과적으로 파라메터를 줄일 수 있지 않을까?
•
Random Synthesizer의 속도가 인상적이다.