"Taming Transformer for High-Resolution Image Synthesis"
Esser, Patrick, Robin Rombach, and Björn Ommer.
arXiv preprint arXiv:2012.09841 (2020).
paper | Project Page | Code
Computer Vision: CNN에서 Transformer로
CNN(Convolutional Neural Networks)은 컴퓨터 비전에서 없어선 안될 모델이면서 아래와 같은 두가지 특징을 가지고 있습니다.
•
강한 지역적 편향 (locality bias) 을 가지고 있습니다.
이는 CNN은 작은 크기의 kernel 을 사용하기 때문입니다.
•
강한 공간 불변성 편향 (bias towards spatial invariance) 이 있습니다.
이는 즉 동일한 CNN커널이 이미지 전체를 처리하기 때문입니다. (shared weight)
Transformer는 inductive bias 가 없다고 말합니다. Transformer는 CNN과 다르게 지역적인 상호 작용 (Local Interaction)을 우선시하여 입력 간의 복잡한 관계를 학습함으로써 이미지를 표현하는데요, 하지만 이런 과정은 long-term sequence에서 계산이 복잡해집니다. (Computationally expensive) Transformer의 표현력이 증가할 수록 계산 복잡도는 제곱으로 증가하게 됩니다.
Transformer가 컴퓨터 비전에 도입되면서, 재미있는 연구들이 많이 나왔습니다. 그 중 TransGAN (Esser et. al. , 2021)은 두 개의 Transformer를 이용하여 CNN의 효과와 Transformer의 표현성을 결합하여 고해상도 Image Synthesis를 하는 논문입니다.
TransGAN: Two Transformers Can Make One Strong GAN
Generative Model의 두가지 관점
한 Dataset X의 true Distribution 에 대하여 가 주어졌을 때, Dataset은 이 분포의 유한 표본 (finite samples)으로 구성됩니다.
Generative Task는 인 모델을 찾는 것입니다. (는 model parameter)
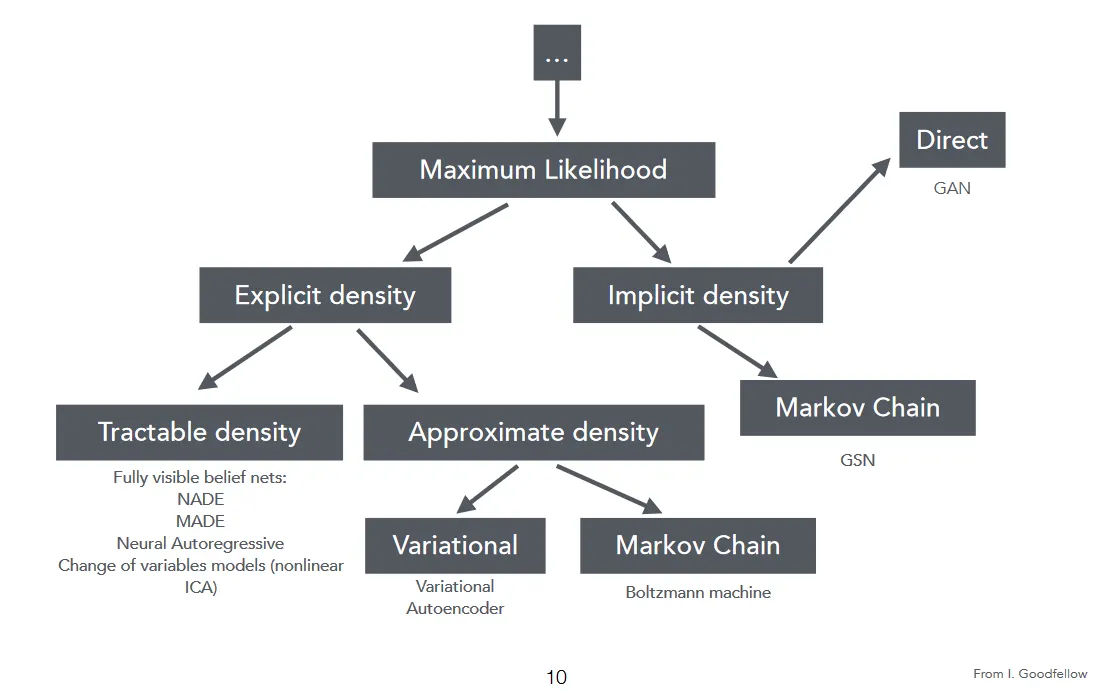
이제 Generative Model을 두가지 타입으로 구분할 수 있습니다.
•
Likelihood-based (explicit) models: 이 모델들은 Data distribution의 parametric specification을 "Explicit", 즉 명료하게 제시합니다. 예시로 Variational Autoencoder (VAEs)와 Autoregressive model들이 있습니다.
•
Implicit Models: 이 모델들은 데이터 distribution 그 자체를 명시하지 않는 대신 (Implicit, 암묵적), 이를 추정해나가는 stochastic process (확률 과정)를 정의합니다. 따라서 학습의 최종 목표는 Dataset에 내제된 분포대로 샘플을 그려주는 것입니다. 예시로 Generative Adversarial Model (GAN) 이 있습니다.
Key Ideas
•
GAN은 Implicit이기 때문에, 평가하기 어렵고 일반적으로 데이터의 모든 "Mode"를 포함하지 못하므로 Model Collapse에 더 취약합니다.
•
Likelihood-based 방법은 training data의 Negative log-likelihood (NLL)을 최적화합니다. 이 덕분에 모델간 비교를 더 쉽게 하고 unseen data에 대한 일반화를 더 잘 수행할 수 있습니다. 하지만, 픽셀 공간에서 likelihood를 최대화하는 것은 어렵고 계산 비용이 많이 듭니다.
•
Conditional GANs (cGANs)는 GAN을 간단하면서도 매우 효과적으로 개선했습니다. GAN의 구조 위에 아주 간단한 Condition (Class, Segmentation map or partial image)을 추가함으로써 이로부터 GAN이 이미지를 생성할 수 있도록 했습니다. [Blog]
Overview of Proposed Method
Limits of Exsisting Method
이 논문이 주목한 Transformer를 사용한 기존 방법의 문제는 다음과 같습니다. 64x64픽셀 크기의 이미지에에서는 괜찮은 결과를 보여주었지만, 더욱 높은 해상도는 처리할 수 없었습니다. 이는 Sequence의 길이에 따라 4차적으로 증가하는 Computation Cost 때문입니다.
Proposed Solution
따라서 Image Synthesis에 Transformer를 사용하려면, 이미지의 의미(Semantic)을 영리하게 표현해야 합니다. Pixel Representation은 Image Resolution에 따라 Pixel 수가 2배 증가하여 Computational Cost가 4차적으로 증가하므로 큰 효과를 기대하기 어렵기 때문입니다.
Related Work Image → Sequence: VQVAE 1 , 2
이 논문은 VQVAE(Aaron, 2017), VQ-VAE-2 (Ali et al.) 를 기반으로 하고 있습니다. VQVAE는 Autoregressive Model로써, latent 를 quantize 해줌으로써 파워풀한 representation learning을 보여주었습니다. VQVAE의 큰 두가지 특징은 다음과 같습니다.
VQVAE
•
Encoder 출력은 Discrete
•
Prior는 Learned
VAE
•
Encoder 출력은 Continuous (latent code)
•
Prior는 Static Multivatriate normal distribution
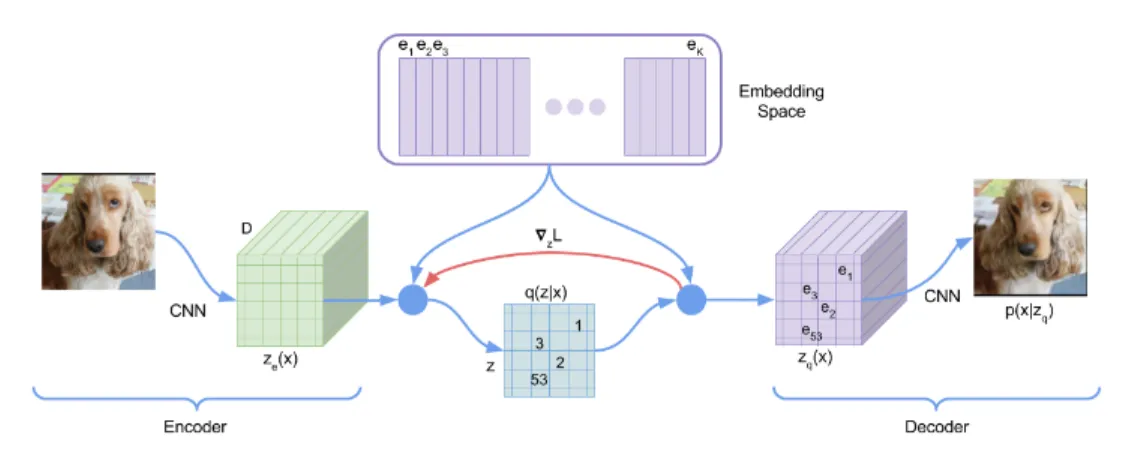
Terminalogies
•
Encoder는 observation (image)을 Discrete latent variable sequence에 Mapping합니다.
•
Decoder는 discrete variables로부터 observation (image)을 복구합니다. (Reconstruction)
•
Codebook은 Encoder와 Decoder 모두가 공유합니다.
•
Encoding 이미지 는 Encoder E에 의해 vector로 만들어집니다.
•
Quantization vector들과 codebook의 code vector들을 비교해 가장 거리가 가까운 nearest code vector 를 찾습니다. 의 각 vector는 nearest code vector 에 해당하는 index 를 기록됩니다. ( )
•
Decoding 같은 방식이 Decoder에서도 이루어집니다.
•
Non-differentiable Quantization은 미분불가능 (non-differentiable)한 과정입니다. 따라서 end-to-end로 학습하기 위해 reconstruction error의 gradient를 Decoder로부터 Encoder로 전파하기 위해서는 straight-through gradient estimator를 사용합니다. (decoder의 gradient를 encoder로 복사하는 방법)
•
Loss는 codebok loss와 commitment loss가 사용되었습니다. codebook loss는 선택된 코드 가 Encoder의 output 에 가깝도록 합니다. commitment loss는 encoder의 output 가 선택된 e에 가깝게 유지되도록 합니다.
Discrete Latent Representation이 작동하는 이유
그렇다면, VQ-VAE-2 (Ali et al.) 이 사용한 Quantization은 왜 효과가 있는걸까요? 이 방법은 JPEG 손실압축에서 영감을 받았습니다. JPEG은 80%의 데이터를 줄여도 이미지 퀄리티에는 큰 차이가 없는 것처럼 느껴집니다. 두번째로, generative model을 노이즈 없이 훈련하는 것이 더 효과적이기 때문입니다.
Related Work Sequence → Image: Autoregressive Generative Models
잠깐, Transformer 이전에도 이미지를 Sequence로 다루는 문제는 많이 있었습니다. 과거에 한창 RNN, LSTM 붐이 일었을때가 생각납니다.
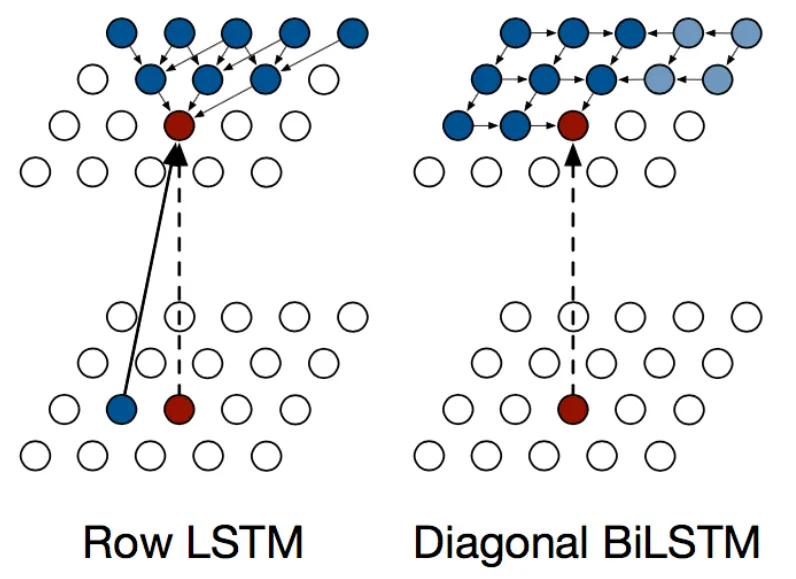
Pixel RNN (ICML, 2016)
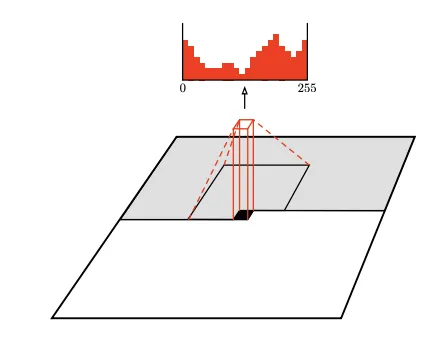
Pixel CNN: Pixel Recurrent Neural Network (arXiv, 2016)
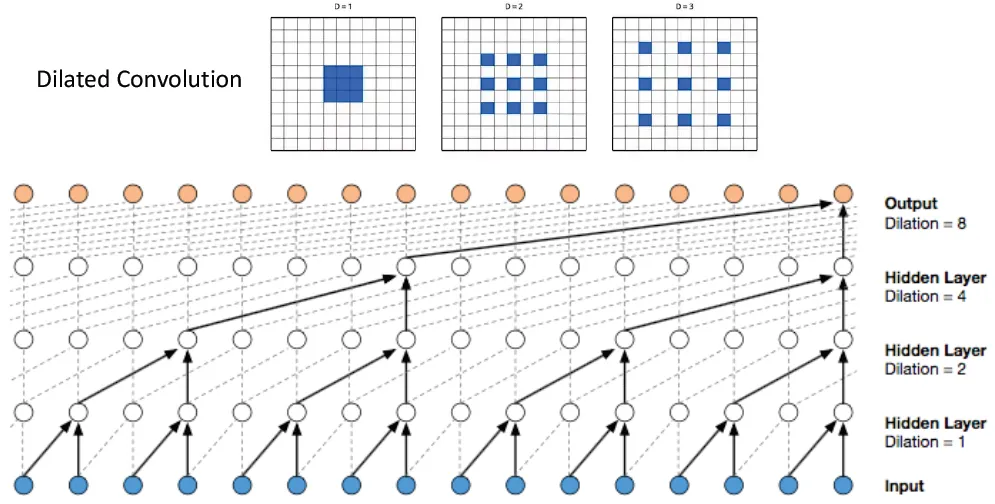
WaveNet
1.
3.
PixelCNN’s blind spot in the receptive field
4.
Gated PixelCNN - Fixing the blind spot
5.
Conditional generation with Gated PixelCNN
6.
Gated PixelCNN with cropped convolutions
7.
PixelCNN++ - Improving performance
8.
Fast PixelCNN++ - Improving sampling time
9.
PixelSNAIL - Using attention mechanisms
10.
VQ-VAE 2 - Generating Diverse High-Fidelity Images
Taming Transformer
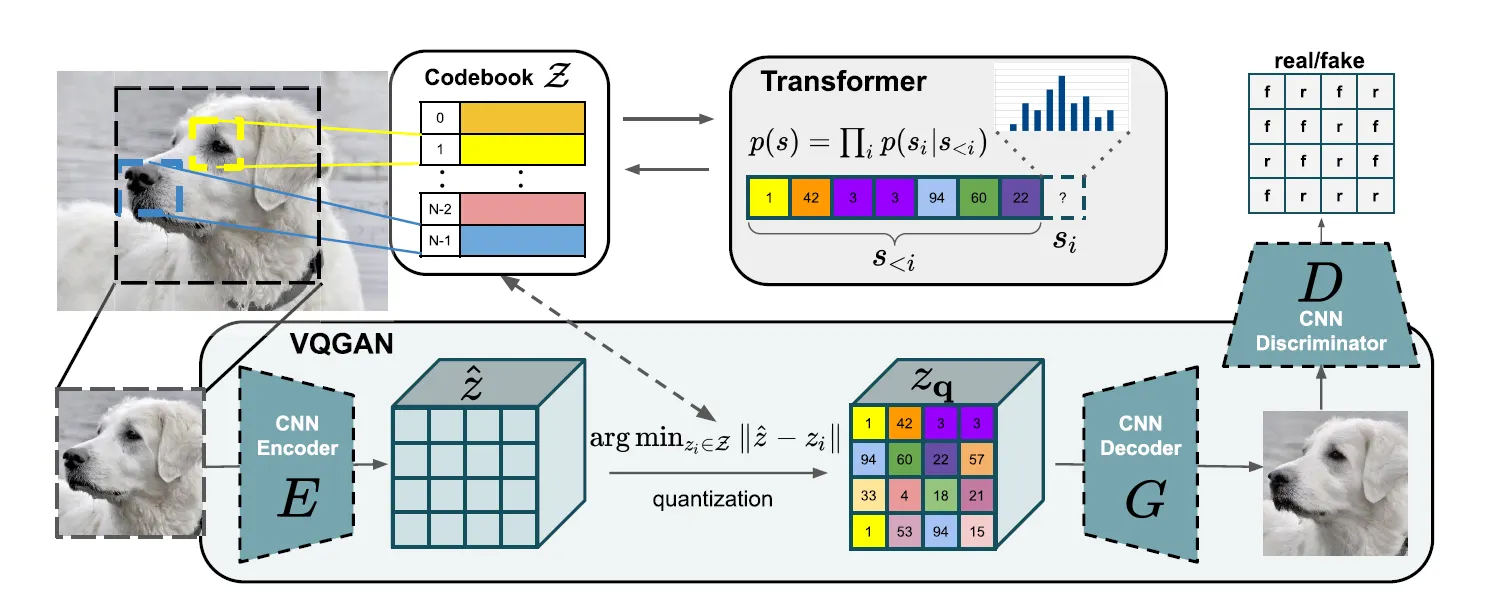
Architecture design of Taming a Transformer.
Terminology
Taming Transformer는 Transformer의 input sequence length를 줄이면서도 표현력(expressivity)을 극대화하는데 초점을 두었습니다. 따라서 VQ-VAE의 codebook을 채용했습니다. codebook의 discrete codebook representation을 이용하여 이미지를 codebook 의 내용으로 표현합니다.
Training Taming Transformer
훈련 과정은 두 단계로 나누어집니다.
1.
VQ-GAN과 quantized codebook을 학습합니다.
2.
autoregressive transformer을 훈련하기 위해 quantized codebook을 sequential input으로 사용합니다.
Training Step 1: Training VQ-GAN
•
Discriminator는 Patch-based Discriminator를 사용합니다.
•
Objective: Optimal Compression Model 는 다음과 같습니다.
•
이러한 훈련과정은 Transformer의 sequence length를 눈에띄게 줄여주어 그 효과를 발휘합니다.
Training Step 2: Training Transformer
VQ-GAN의 훈련이 끝났다면, 학습된 Encoder와 Decoder가 있습니다. 이제 이미지를 codebook index로 표현할 수 있게 되었습니다.
이제 이 인코딩을 sequence로 표현합니다.

이때 주의할 점은, encoding된 벡터 그 자체가 아니라 vector의 index만을 가지고 온다는 점입니다.
이미지 인코딩 가 code book에서 가장 가까운 vector인 로 quantized 되어 가 되는데, sequence 에는 index 를 써넣습니다. 그렇다면 이를 다시 디코딩 할때 코드북을 참조하여 디코더로 들어갑니다.
•
이 sequence로부터 image-generation 문제는 autogrgressive next-index prediction 문제로 re-formulate 될 수 있습니다.
•
Transformer는 주어진 indices 에 대해 다음 indices의 distribution 를 학습합니다.
•
그후 full-representation의 likelihood를 계산합니다.
따라서 objective function은 data representation의 log-likelihood를 최대화하는 것입니다. (likelihood에 대한 글은 이 포스트를 참고하세요.)
Image Generation System은 사용자가 컨트롤할 수 있다면 매우 유용할 것입니다. 사용자가 원하는 정보는 class label이나 일부 이미지의 형태인 condition으로써 주어집니다. condition이 주어지면 task는 다음과 같이 formulate됩니다.
Generating High-Resolution Images
Transformer의 문제 중 하나는, computational cost가 input image 길이에 대해 4차적으로 증가하는 것이라고 언급했습니다. 따라서 고해상도로 이미지를 복구하기 위해서 저자는 이미지 전체를 사용하지 않고, 이미지를 patch-wise로 잘라내어 훈련 가능한 최대 sequence 길이만큼만 사용했습니다. 이때 sliding-window 를 적용하였습니다.

VQ-GAN은 이 방법이 dataset의 statistic가 spatially invariant하거나 spatial conditioning information이 가능한 경우에는 이미지를 생성하기에 충분하다고 보장합니다. (은근슬쩍 넘어가는 느낌이 들지만..)
My Thoughts
그렇다면, Contribution은 이곳이지 않을까?
•
latent code이지만 sequence의 길이를 충분히 받지 못해 한정된 windowed로만 받아야 한다
•
그렇다면 어떤 것들을 선택적으로 받을 것인가?
•
Attention?
•
Latent Code를 복구할때 깊은 곳에서 Transformer, 그렇다면 얕은 곳에서는?
•
Ventral: 장기: 물체의 색, 형태를 기존 영상과 비교하면서 판단
•
Dorsal: 단기: 위치, 빠르기, 거리 + 눈의 움직임, 몸의 움직임
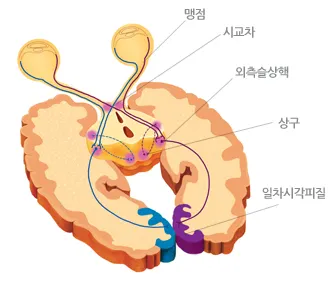
•
빛 → 눈 → 동공 → 망막 → 전기신호 → 맹점 → 신경다발 → 시교차 → 뇌 ( 좌뇌 / 우뇌 )
•
오른쪽 눈 → 좌뇌 (시각교차) → 외측슬상핵 → 시신경방사 → 일차시각피질 → 중뇌 상구